作业要求
在 OpenGauss 数据库中, 完成以下内容.
- 数据库维护
- 性能检查
- SQL优化
- 日志管理
- 备份与恢复
- 物理备份
- 逻辑备份
- 数据库恢复
准备工作
由于 OpenGauss 的部分维护功能只在 企业版 中可用,因此在轻量版中无法完成本次作业的部分内容:
- 物理备份
- 数据库恢复
因此, 为完成本次作业, 需要将 OpenGauss 切换到企业版.
由于本人在先前的实验中使用了 Docker 和 Docker Compose 工具进行了容器化的 OpenGauss 的部署, 而两个版本的 OpenGauss 数据文件相互兼容, 因此只需要将 docker-compose.yml 中的 image 字段修改为企业版的镜像, 即可完成版本的切换.
| |
修改完成后, 使用 docker-compose up -d 命令重新启动容器, 即可完成版本的切换. 由于相同版本间, 轻量版与企业版的数据基本兼容, 因此原有数据不会丢失.
操作系统参数检查
由于部署在 Docker 容器中的 OpenGauss 无需考虑 服务器的物理资源限制, 在成熟可靠的镜像中也不会遇到系统配置对数据库的影响, 因此这一部分内容在华为云的 ECS 上进行测试. 系统为 Huawei OpenEuler 20.09, 安装的 OpenGauss 版本同样为 企业版 5.1.0.
| |
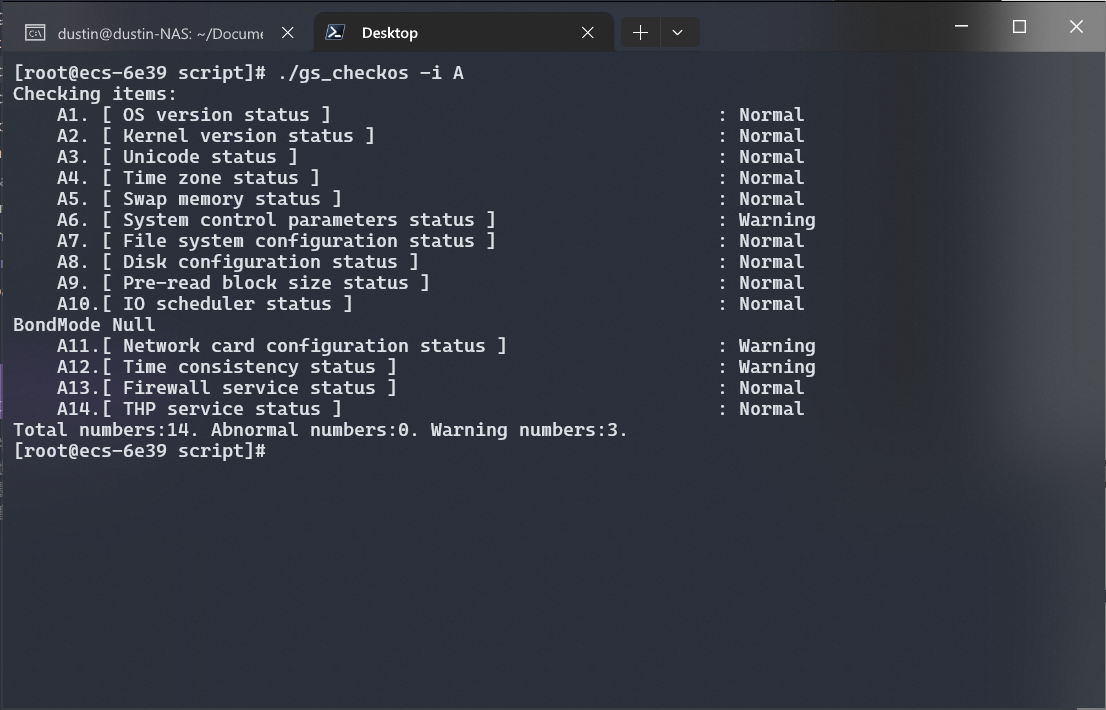
使用 OpenGauss 提供的 gs_checkos 脚本, 检查操作系统的兼容性. 该脚本会检查操作系统版本、内核版本、文件系统类型等信息, 确保系统满足 OpenGauss 的运行要求.
返回结果中, Normal 表示正常, Warning 表示警告, Abnormal 表示错误. Abnormal 为必须处理项, Warning 可以不处理.
在参数配置文件 (/etc/sysctl.conf) 中将参数 vm.min_free_kbytes (表示内核内存分配保留的内存量, 以保证物理内存有足够空闲空间,防止突发性换页) 的值调整为3488.
再次执行 gs_checkos, 此时 A6. [ System control parameters status ] 的状态是 Warning 为告警项;
vm.min_free_kbytes = 3488 修改后的信息会暴露在告警项中, 通过详细信息可以查看到.
| |
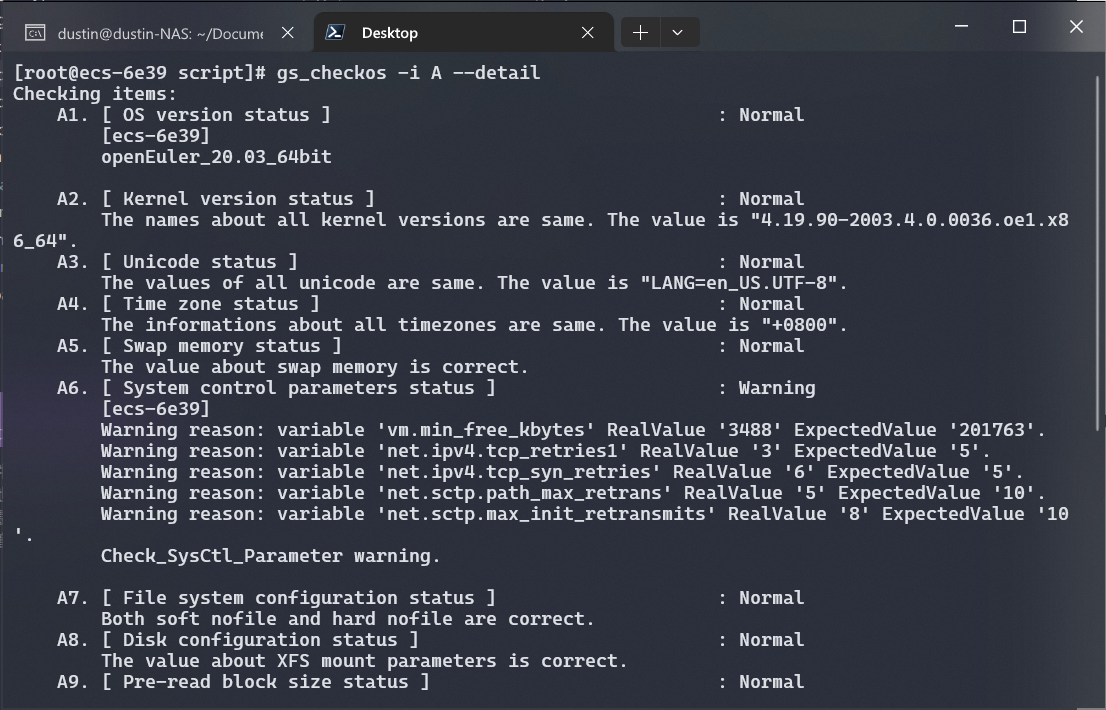
可以看见, 详细信息中显示了 vm.min_free_kbytes 的值过小的警报, 同时也给出了建议的最小数值为 201763.
根据给出的建议, 我们可以将所有警报项的值都设置为建议值或以上, 以免影响数据库的正常运行.
数据库维护
常规维护工作
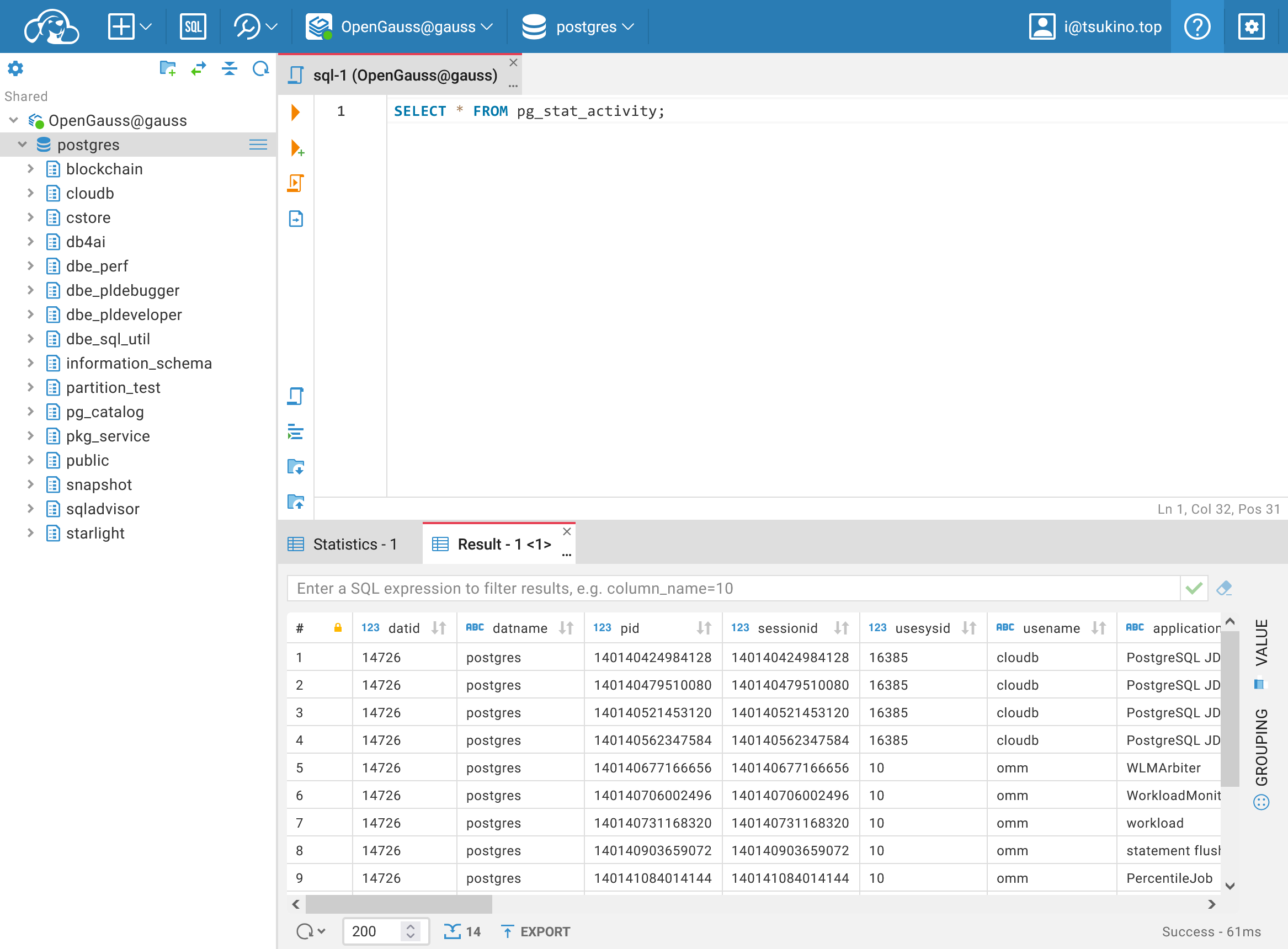
通过 pg_stat_activity 检查活动连接
在 OpenGauss 中,可以使用 pg_stat_activity 视图来检查当前活动的连接。以下命令查看当前所有活动连接的信息:
| |
通过 ANALYZE 维护统计信息
在 OpenGauss 中,可以使用 ANALYZE 命令来更新表的统计信息,以帮助查询优化器选择最佳的执行计划。以下命令对 xs 表进行统计信息更新:
| |
由于优化器依赖统计信息生成最佳执行计划, 因此在数据发生大量变化时, 需要更新统计信息, 以确保查询性能。
通过 VACUUM 进行表维护
数据库中, 默认情况下已被删除或已被覆盖的行仍然会占用储存空间以备事务回滚或数据库闪回. 但在长期大量的删改操作后, 数据库中会存有大量无用过时数据. 这时可以使用 VACUUM 命令来回收已删除或更新的行占用的空间,减少表膨胀。
例如, 假设 xs 表中有大量的删除和更新操作,可以使用以下命令来回收空间:
| |
使用 REINDEX 维护更新索引
在数据表发生大量的增改后, 可能会导致索引失效或性能下降。可以使用 REINDEX 命令来重建索引,以提高查询性能。
例如, 假设 xs 表的索引 idx_xs_pkey 需要重建,可以使用以下命令:
| |
在大量数据删除或索引膨胀后执行 REINDEX, 可以有效地减少索引的大小和提高查询性能。
性能检查
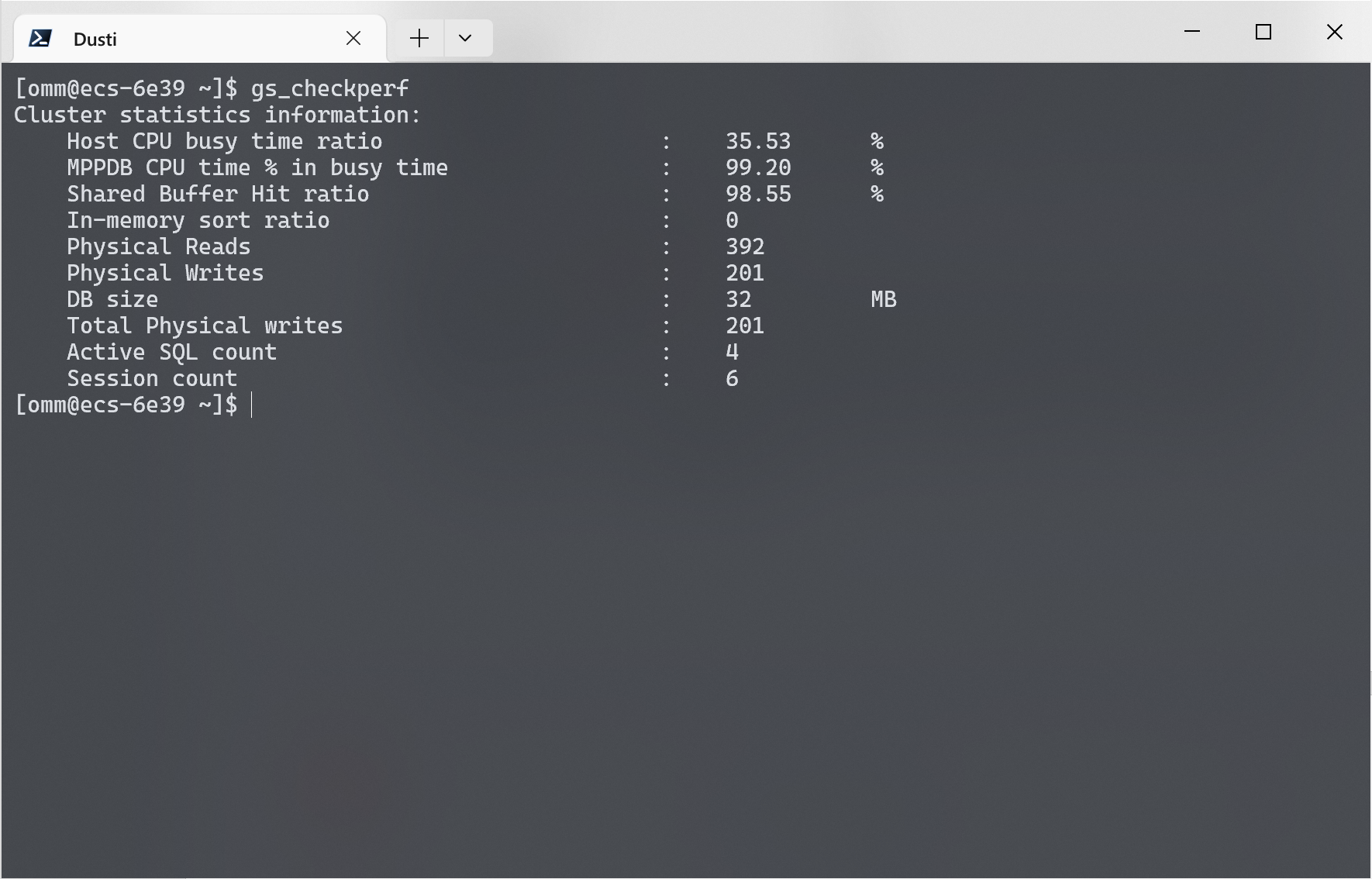
登录到服务器之后, 使用 gs_checkperf 命令检查性能, 该命令会检查数据库的性能, 包括内存使用情况、IO使用情况、CPU使用情况等。
gs_checkperf 工具的监控信息依赖于 PMK 模式下的表的数据,如果 PMK 模式下的表未执行 ANALYZE 操作,则可能导致gs_checkperf工具执行失败。
连接到数据库之后, 使用 ANALYZE 命令收集性能统计信息.
| |
执行完成后, 断开数据库连接, 使用 gs_checkperf 命令检查性能. 如果需要详细性能信息, 使用 gs_checkperf --detail 命令.
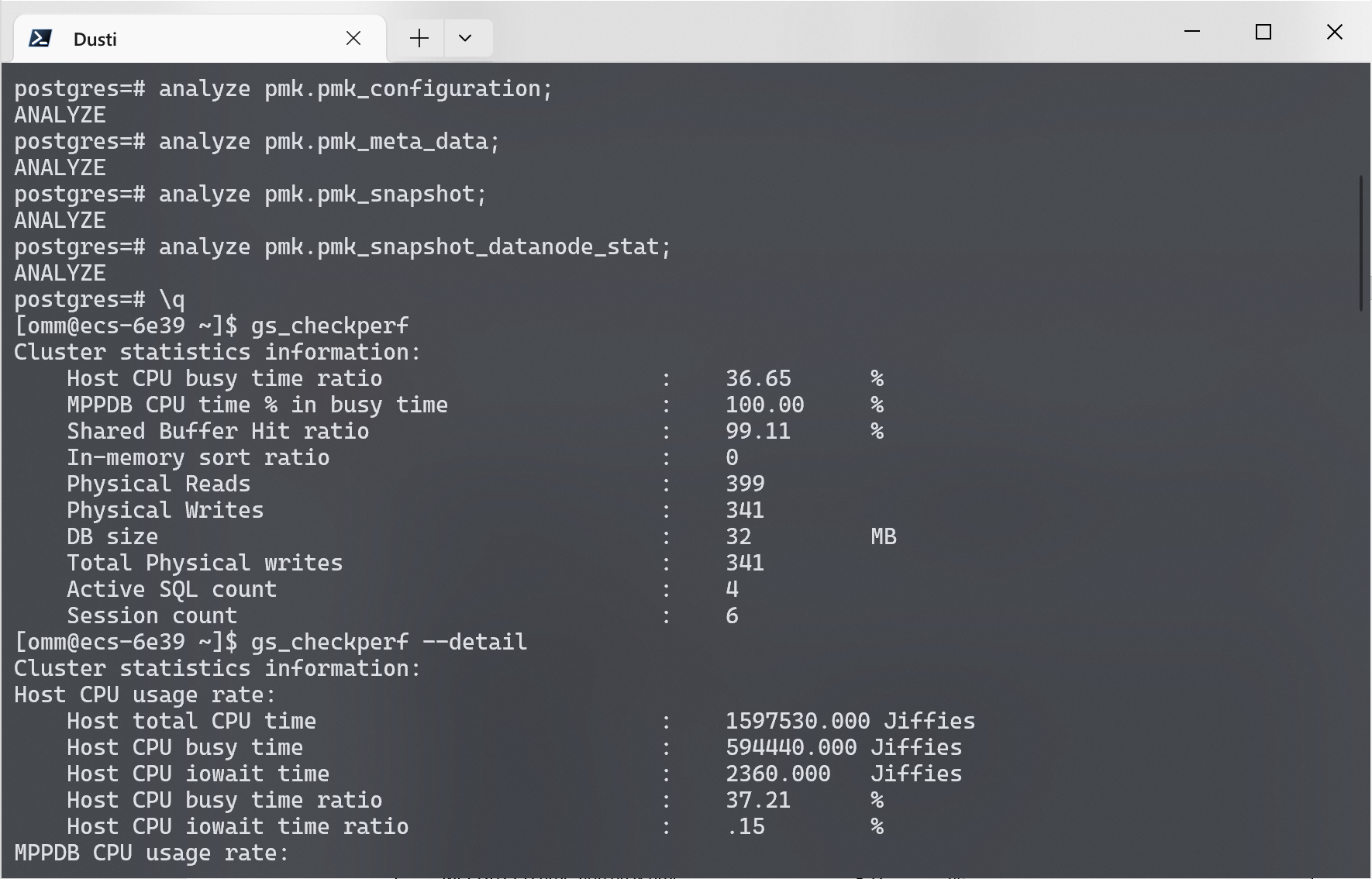
得到的具体性能信息如下:
#raw( read(“assets/checkperf-detail.log”), block: true, )
使用 EXPLAIN 进行 SQL 优化
使用 EXPLAIN 命令分析 SQL 语句的执行计划, 进而对数据库和 SQL 语句进行优化. EXPLAIN 命令会显示 SQL 语句的执行计划, 包括访问路径、连接方式、索引使用情况等。
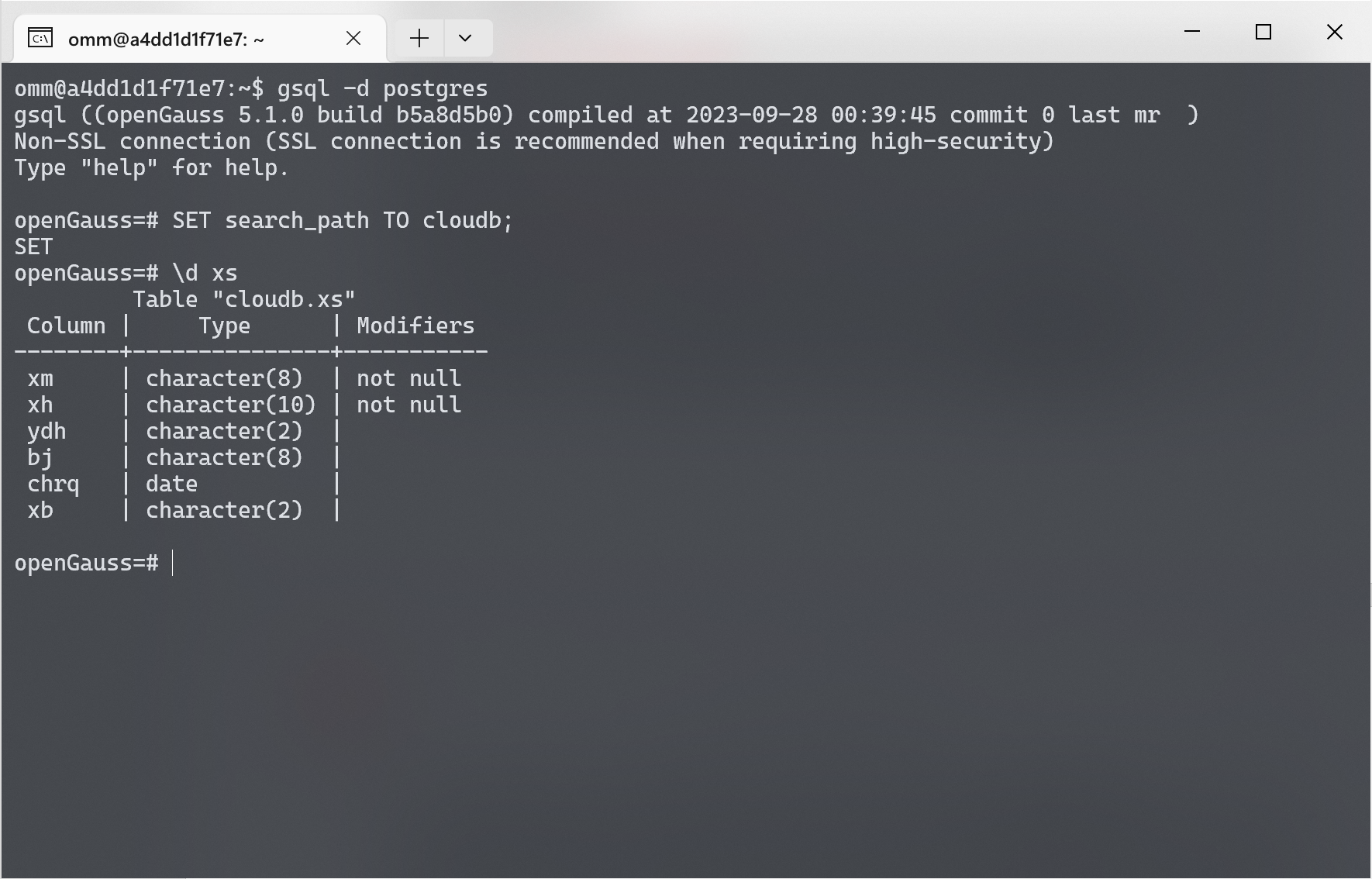
本次沿用实验中使用的 “学籍与成绩管理系统” 作为实验对象. 由于需要通过创建索引来实现对数据库性能的优化, 因此先删除原有的带索引表格, 重新创建无索引的表格.
| |
创建完成后, 使用 \d xs 命令查看 xs 表的信息.
使用 ANALYZE 命令收集性能统计信息.
| |
使用 EXPLAIN 命令分析 SQL 语句的执行计划.
| |
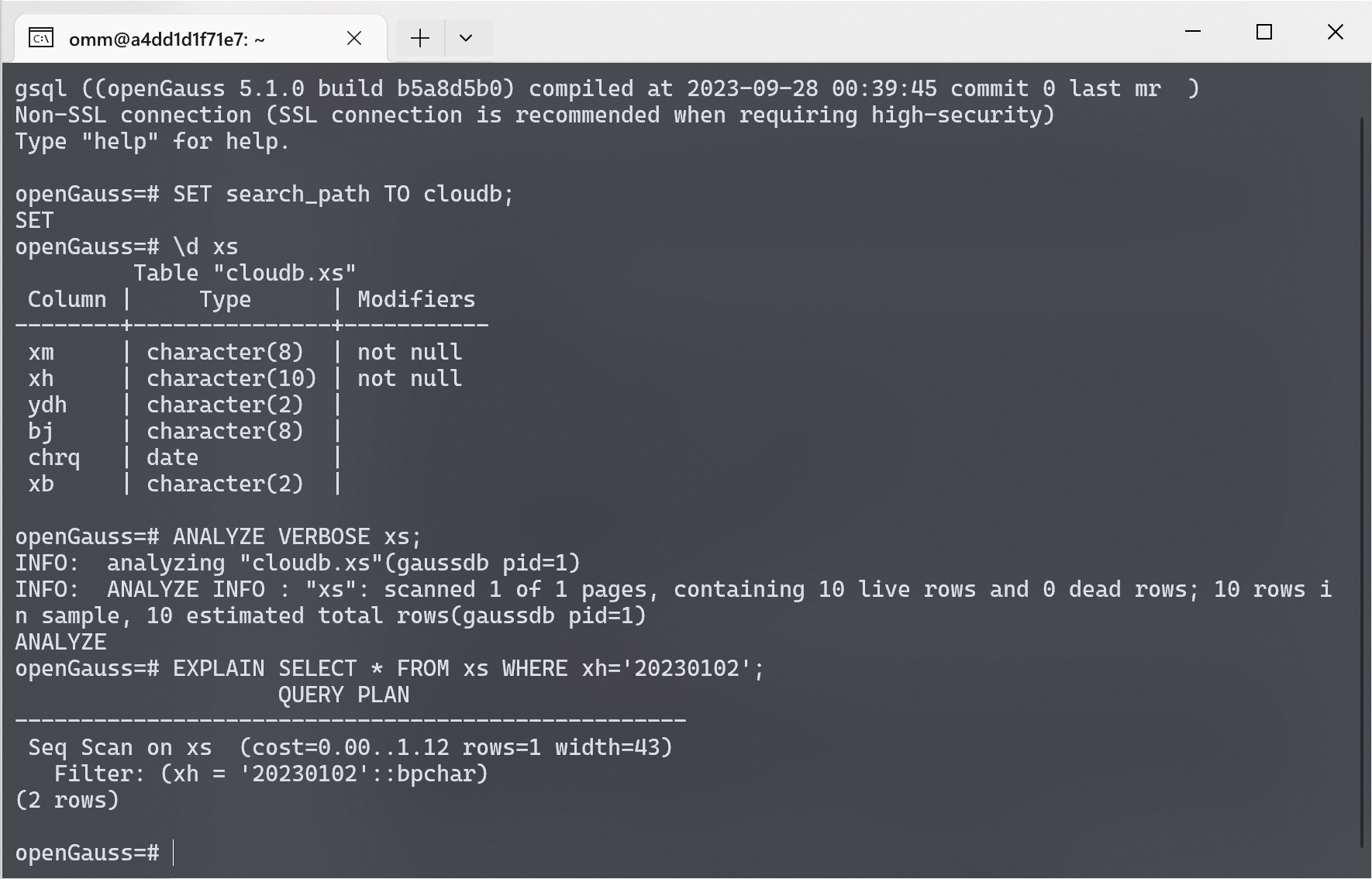
可以看见, 由于表格没有索引, 因此使用的是 Seq Scan 顺序扫描的方式来进行查询. 在大数据量的情况下, 这种方式会导致性能表现较差.
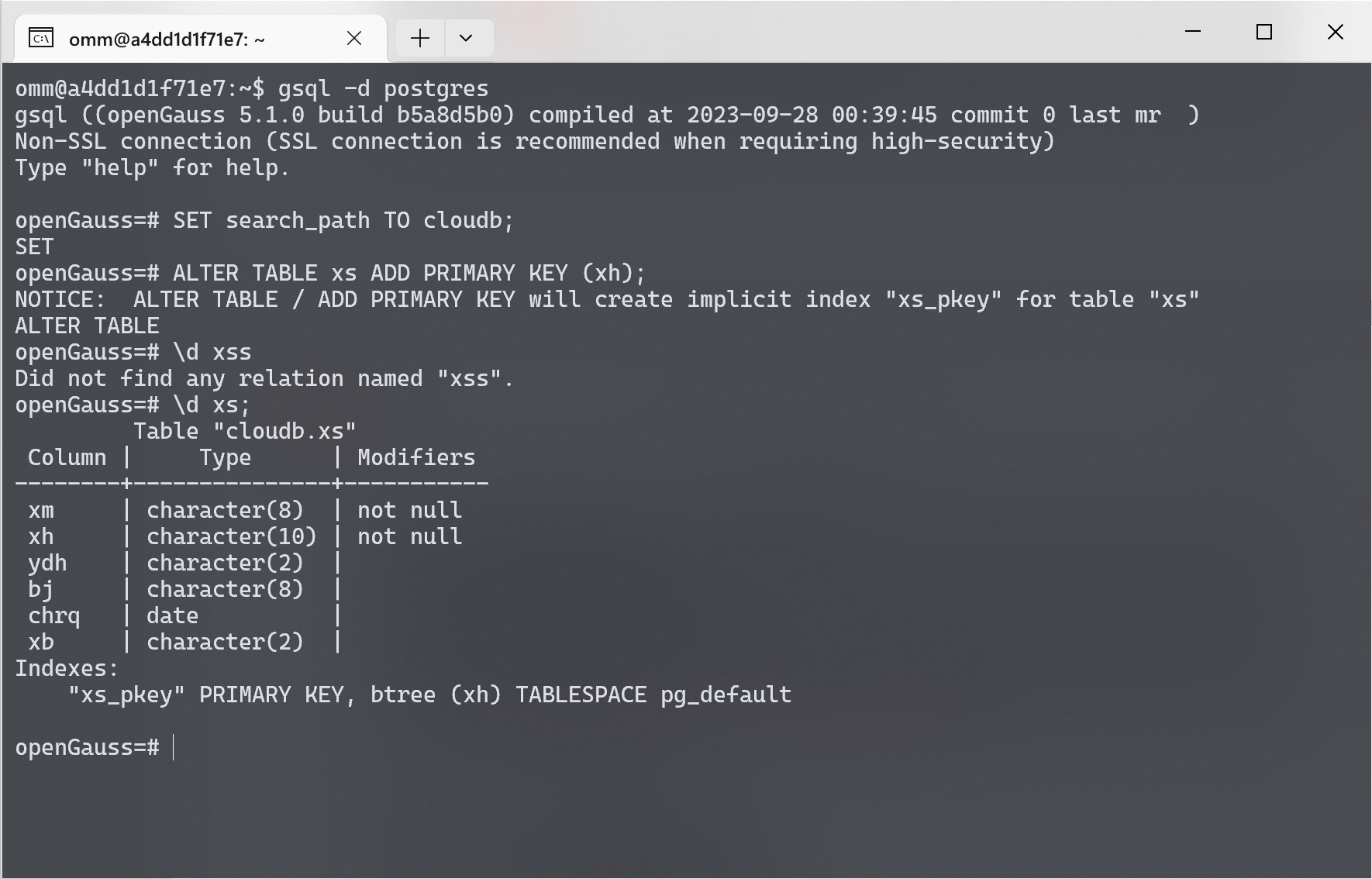
使用下面的命令为 xs 表创建主键.
| |
创建完成后, 使用 \d xs 命令查看 xs 表的信息. 可以看见, xh 列已经被添加了主键约束, 并且已经被自动创建了索引 xs_pkey.
此时, 通过添加 Hint 来优化 SQL 语句的执行计划.
| |
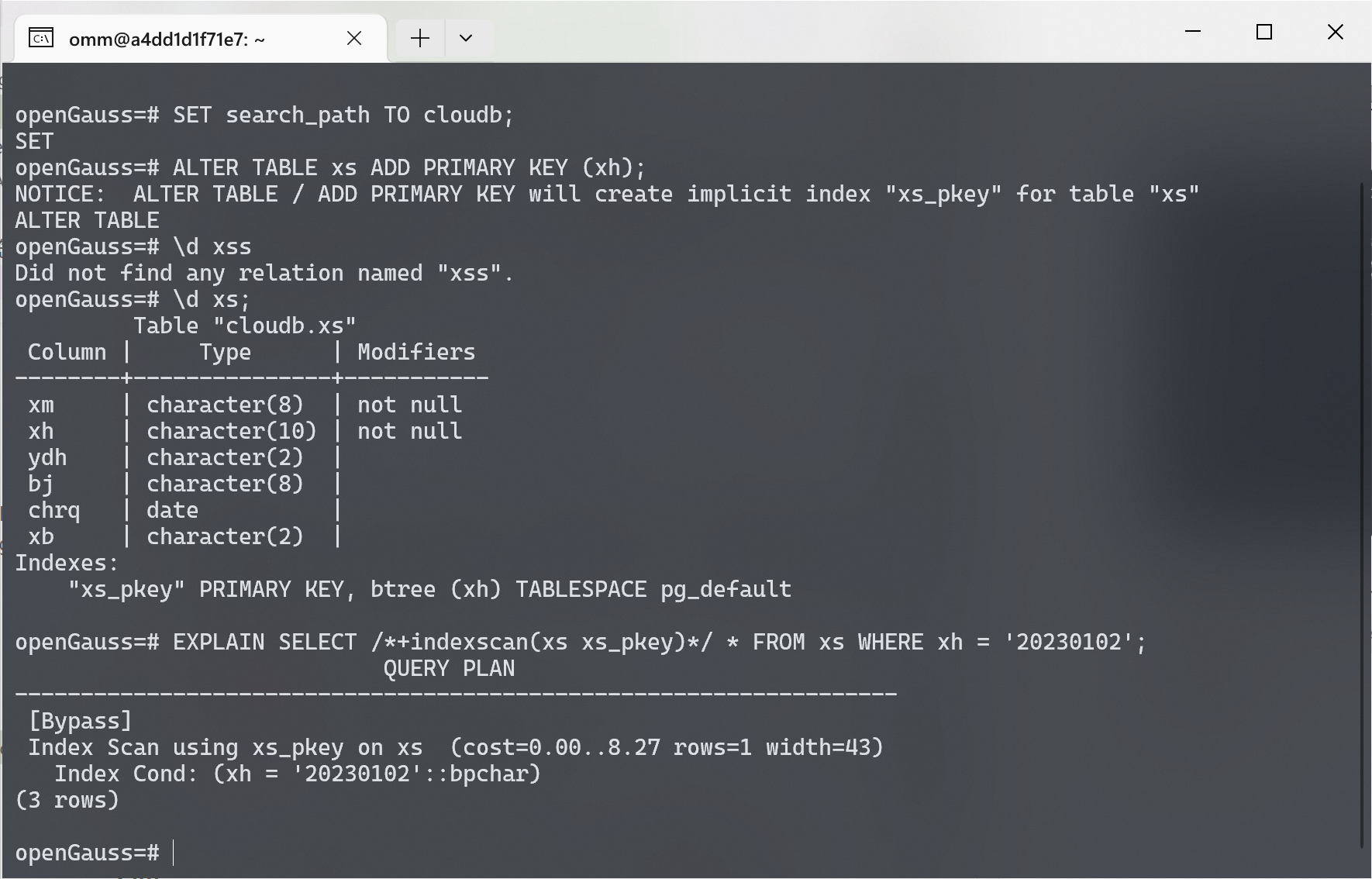
可以看到, SQL 语句的执行计划已经发生了变化, 变成了 Index Scan 索引扫描的方式来进行查询. 这种方式在大数据量的情况下, 性能表现会更好.
日志管理
数据库运行时,某些操作在执行过程中可能会出现错误,数据库依然能够运行。但是此时数据库中的数据可能已经发生不一致的情况。建议检查 OpenGauss 运行日志,及时发现隐患。
当 OpenGauss 发生故障时,使用 gs_collector 此工具收集OS信息、日志信息以及配置文件等信息,来定位问题。
本次先手工设置收集配置信息,然后通过 gs_collector 工具调整用配置来收集相关日志信息。
登录到服务器后, 创建 collector.json 配置文件, 内容如下:
| |
然后执行 gs_collector 命令, 进行收集:
| |
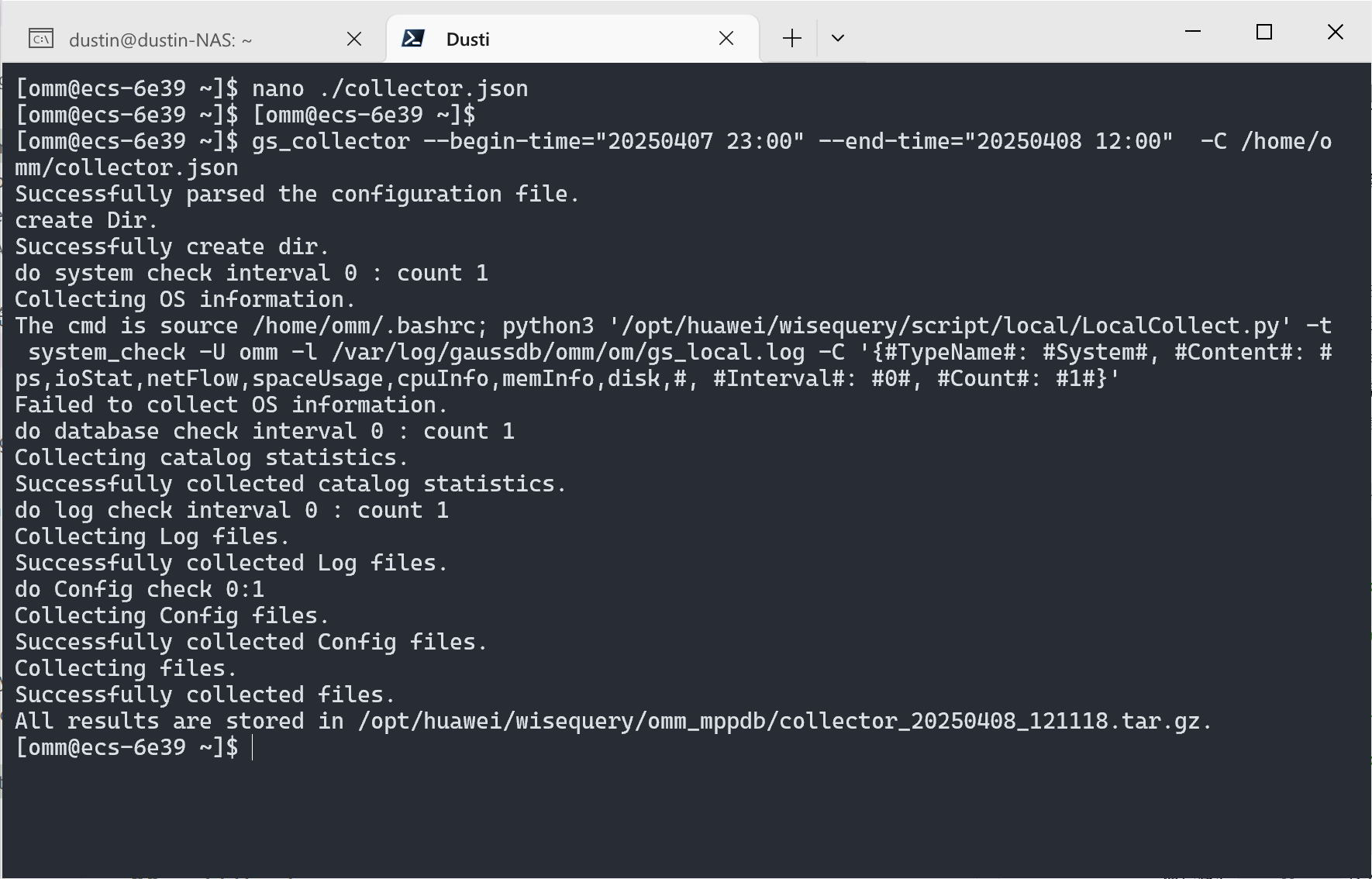
可以看见日志被导出到了 /opt/huawei/wisequery/omm_mppdb/ 目录下的压缩文件中. 为方便查看, 可通过 scp 命令将其复制到本地.
| |
解压日志文件后, 目录结构如下:
COLLECTOR_20250408_121118
│ Detail.log
│ Summary.log
│
└───ecs-6e39
├───catalogfiles
│ dn_6001_pg_locks_20250408_121120632991.csv
│ dn_6001_pg_stat_activity_20250408_121120831763.csv
│ dn_6001_pg_thread_wait_status_20250408_121121030174.csv
│ gs_clean_20250408_121121235082.txt
│
├───configfiles
│ └───config_20250408_121122396664
│ └───dn_6001
│ │ gaussdb.state
│ │ pg_control
│ │ pg_hba.conf
│ │ pg_ident.conf
│ │ postgresql.conf
│ │
│ └───pg_replslot
├───coreDumpfiles
├───gstackfiles
├───logfiles
│ log_20250408_121121810369.tar.gz
│
├───planSimulatorfiles
├───systemfiles
│ database_system_info_20250408_121118913879.txt
│ OS_information_20250408_121118891142.txt
│
└───xlogfiles
根据需要, 可以查看 catalogfiles 目录下的各个 csv 文件, 其中包含了锁信息、活动会话信息、线程等待状态等信息. 也可以查看 logfiles 目录下的日志文件, 其中包含了数据库的运行日志.
备份与恢复
物理备份
要进行物理备份, 需要先创建一个备份文件夹, 假设为 ~/physicalBackup。然后, 使用 gs_basebackup 命令进行备份。
| |
运行命令之后, 等待执行完毕. 备份完成后, 可以在 ~/physicalBackup 目录下找到备份文件.
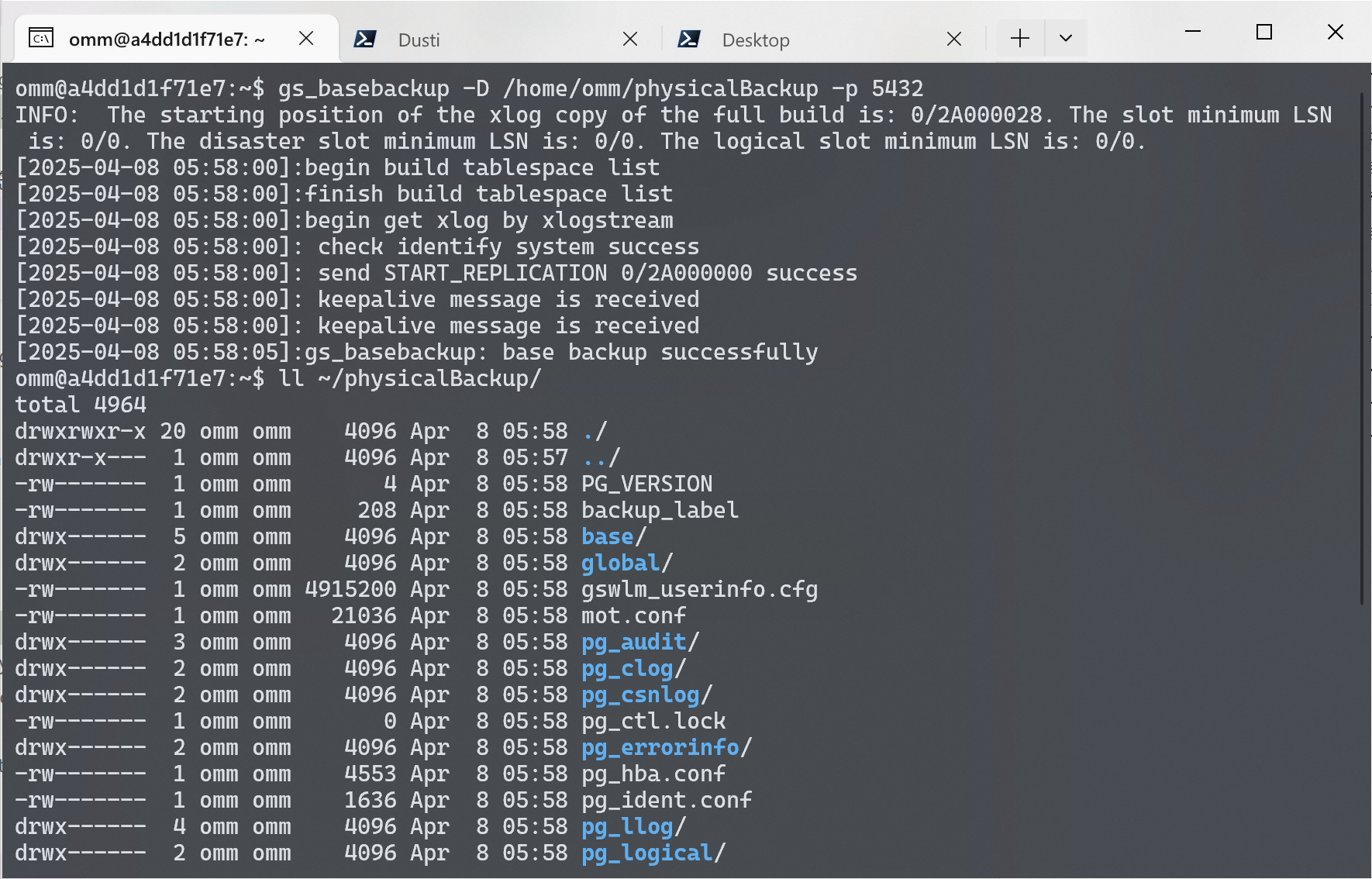
物理恢复
当数据库发生故障时, 可以从备份文件进行恢复. 由于 gs_basebackup 命令是对数据库按二进制进行备份,因此恢复时可以直接拷贝替换原有的文件,或者直接在备份的库上启动数据库.
为防止数据库运行时对文件加锁, 需要先停止数据库, 再进行备份数据的替换.
| |
这样进行物理恢复后, 数据应会恢复到备份时的状态.
逻辑备份
使用 gs_dump 对指定数据库进行逻辑备份
逻辑备份是通过导出数据库对象定义和内容的方式进行数据备份。与物理备份相比,逻辑备份具有以下特点:
时间点一致性:逻辑备份只能保存备份时刻的数据状态,无法记录故障点和备份点之间的变更。
适用场景:最适合备份相对静态的数据。当数据因误操作被破坏时,可以通过逻辑备份快速恢复特定对象。
恢复限制:进行全库恢复时,通常需要重建数据库实例并导入备份数据。对于高可用性要求的生产环境,由于恢复时间较长,不建议作为主要恢复方案。
平台兼容性:由于逻辑备份是以 SQL 或特定格式文本形式存储,具有良好的平台兼容性,常用于数据库迁移和跨平台部署。
#linebreak()
在 OpenGauss 中, 可以使用 gs_dump 工具进行逻辑备份. gs_dump 工具支持多种格式的备份, 具体格式如下:
#table( columns: (1fr, 0.5fr, 2fr, 1fr, 1.5fr), align: horizon,
[格式名称], [-F 的参数数值], [说明], [建议], [对应导入工具],
[纯文本格式], [p], [纯文本脚本文件包含 SQL 语句和命令。命令可以由 gsql 命令行终端程序执行,用于重新创建数据库对象并加载表数据。], [小型数据库,一般推荐纯文本格式。], [使用 gsql 工具恢复数据库对象前,可根据需要使用文本编辑器编辑纯文本导出文件。],
[自定义归档格式], [c], [一种二进制文件。支持从导出文件中恢复所有或所选数据库对象。], [中型或大型数据库,推荐自定义归档格式。], [],
[目录归档格式], [d], [该格式会创建一个目录,该目录包含两类文件,一类是目录文件,另一类是每个表和 blob 对象对应的数据文件。], [无], [使用 gs_restore 可以选择要从自定义归档导出文件中导入相应的数据库对象。],
[tar 归档格式], [t], [tar 归档文件支持从导出文件中恢复所有或所选数据库对象。tar 归档格式不支持压缩且对于单独表大小应小于 8GB。], [无], [],
)
要对数据库进行逻辑备份, 需要先创建一个备份文件夹, 假设为 ~/logicalBackup。然后, 使用 gs_dump 命令进行备份. 由于数据库较小, 这里我们使用纯文本格式进行备份.
| |
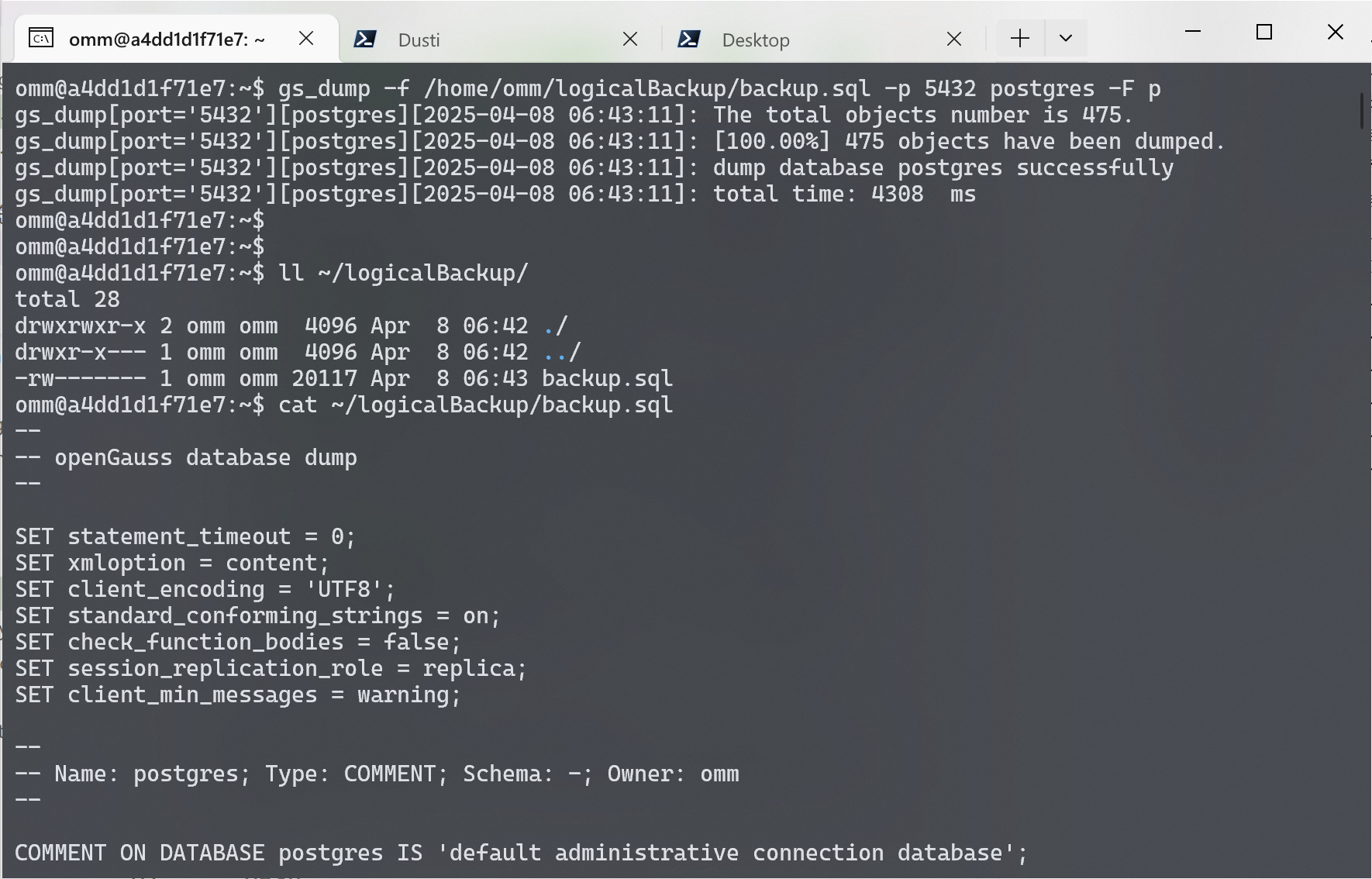
可以看到, 由于我们在进行逻辑备份时指定了备份格式为 p, 即纯文本格式进行逻辑备份, 因此备份文件的后缀名为 .sql, 其中储存着用于重建数据库的全部 SQL 语句.
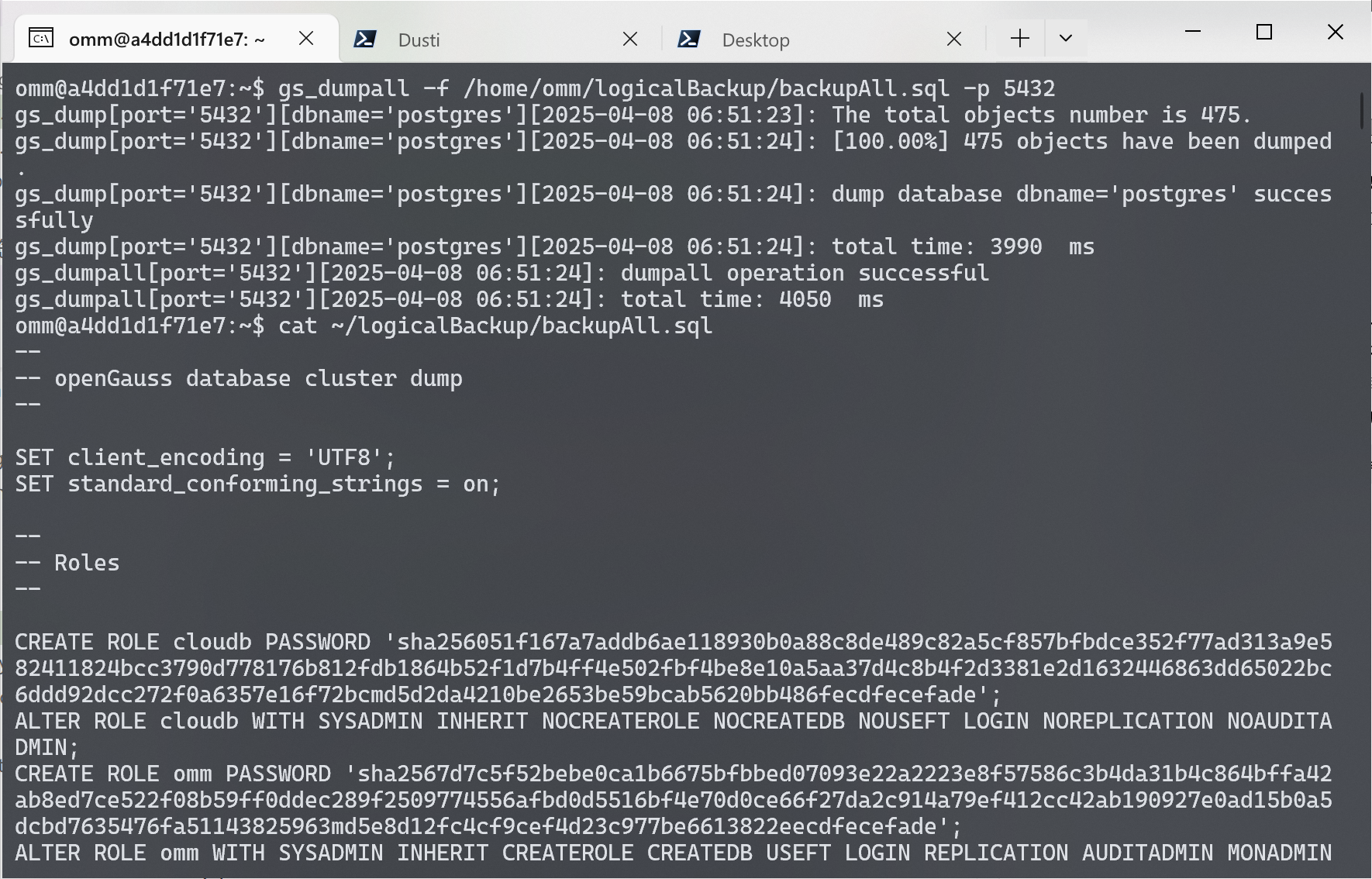
使用 gs_dumpall 对所有数据库进行逻辑备份
gs_dumpall 可以导出 Open Gauss 数据库的所有数据,包括默认数据库 postgres 的数据、自定义数据库的数据、以及 Open Gauss 所有数据库公共的全局对象。
在导出时分为两部分:
- 对所有数据库公共的全局对象进行导出,包括有关数据库用户和组,表空间以及属性(例如,适用于数据库整体的访问权限)信息。
- 调用
gs_dump来完成各数据库的SQL脚本文件导出,该脚本文件包含将数据库恢复为其保存时的状态所需要的全部SQL语句。
| |
逻辑恢复
在通过 gs_dump 进行逻辑备份后, 可以使用 gs_restore 命令进行逻辑恢复. gs_restore 命令可以从 gs_dump 生成的转储文件中恢复数据库对象和数据.
需要注意的是, 恢复数据时为防止数据的覆盖或是对象冲突, 需要先创建一个新的数据库, 然后再进行数据的恢复.
例如, 将 backup.sql 文件中的数据恢复到 recovery 数据库中, 先需要创建一个新的数据库 recovery:
| |
创建完成后, 连接到 recovery 数据库, 然后使用 \i 命令读取 SQL 文件进行数据恢复:
gsql -d recovery
\i /home/omm/logicalBackup/backup.sql
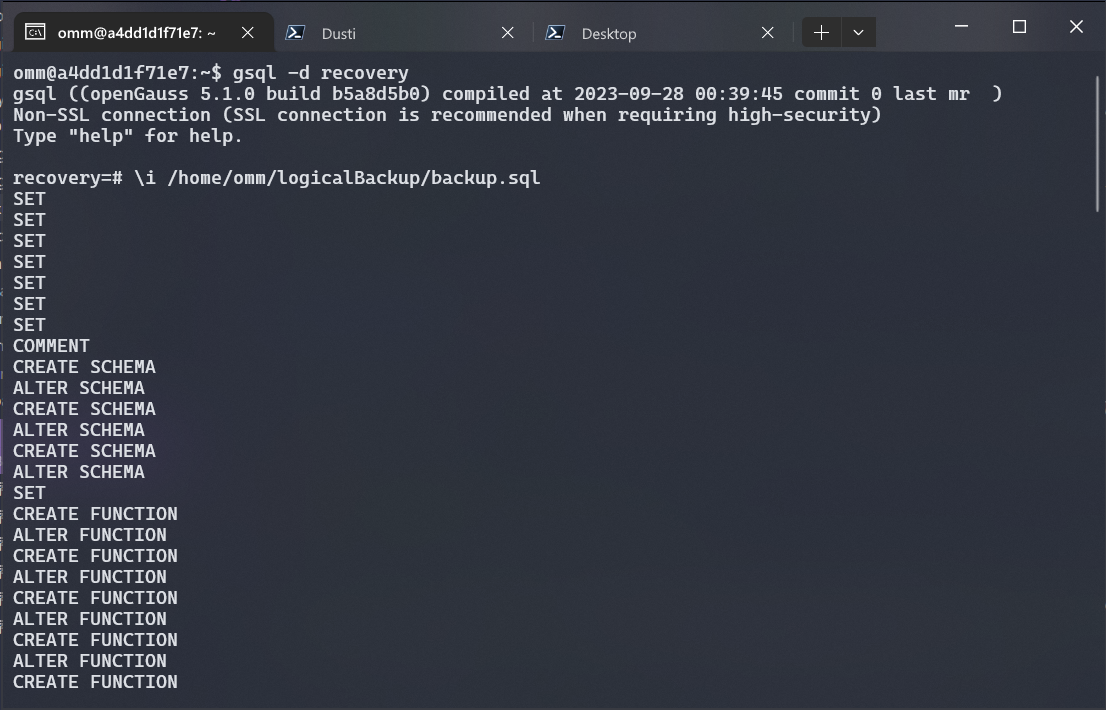
需要注意的是, 由 gs_dump 生成的转储文件不包含优化程序用来做执行计划决定的统计数据. 因此, 最好从某转储文件恢复之后运行 ANALYZE 以确保最佳效果. 转储文件不包含任何 ALTER DATABASE ... SET 命令, 这些设置由 gs_dumpall 转储.
总结与体会
通过本次实践,我深入了解了数据库管理员的日常工作内容,掌握了数据库维护和备份恢复的基本技能:
- 数据库维护方面:
- 掌握了使用
pg_stat_activity检查数据库活动连接的方法 - 学会了通过
ANALYZE和VACUUM命令进行数据库维护 - 理解了使用
EXPLAIN命令分析和优化 SQL 语句的重要性 - 熟悉了数据库日志管理的相关工具
- 备份恢复方面:
- 掌握了物理备份的方法和注意事项
- 学会了使用不同格式进行逻辑备份
- 理解了数据库恢复的流程和细节
此次实践让我认识到数据库管理不仅需要掌握必要的技术知识,更需要有预防和应对故障的意识。通过定期维护和备份,才能确保数据库的安全可靠运行。同时,对数据库性能的监控和优化也是一项重要的日常工作。
总的来说,这次实践加深了我对数据库管理工作的理解,为今后从事相关工作打下了良好基础。