作业要求
在 OpenGauss 数据库中, 完成以下内容.
- 设计实现 “北京理工大学教学系统”, 要求能实现以下功能:
- 处理学生专业变动
- 学科数据字典设计
- 处理编码长度改变
- 如一级学科变成3位
- 编码方式改变
- 增加四级学科、将门类与一级学科合并
- 代码有效期改变
- 如某个二级学科从 2010 年 10 月 1 日开始不再使用
- 代码被覆盖或替换
- 如081202(计算机软件与理论)改变为软件工程,新增081204(计算机软件与理论)
- 要求保留原信息
- 在引用数据字典的表中的信息,要能查询到某人在2010年10月1日前的学科为计算机软件与理论,之后依然不变
- 但籍贯会发生变化(四川$->$重庆)(1997)
- 处理编码长度改变
- 进行学生成绩展示
- 显示成绩单
- 不使用 DBMS 提供的
CROSS方法,实现交叉表查询
设计学科表
数据结构设计
中华人民共和国学科分类指以国家标准为形式发布的学科分类方式及名称提法。学科分类采用树形结构, 一级学科下设二级学科,二级学科下设三级学科,如此类推。每一级均有其编码与名称:
- 一级学科: 2 位数字编码, 如 “01” 表示 “哲学”
- 二级学科: 4 位数字编码, 前 2 位为对应一级学科编码, 后 2 位为本学科编号
- 如此类推, 三级学科编码为 6 位数字, 四级学科编码为 8 位数字
此编码方式便于管理与扩展, 也方便检索上下级关系. 例如, “010102” 编码可直观地看出属于 “01” 哲学一级学科下的 “01” 哲学类二级学科下的 “02” 逻辑学。
但随着学科分类的不断发展,学科编码也在不断变化。例如,新设立的学科可能会使用已经消失的旧学科的编号,三级学科可能会变更为二级学科等。
由于学科编号与所有大学毕业生的学位证书、学籍档案等密切相关,在某次变更前毕业的学生,其学位证书上可能会使用旧的学科编码,而在变更后毕业的学生则使用新的学科编码。因此学科编码的变更需要有明确的可追溯性,以便于在查询时能够准确地找到对应的学科信息。
考虑到学科编码结构的特殊性、对可追溯性的特殊要求,将数据表设计如下:
| |
下面对表中各处设计进行详细说明:
数据嵌套
在作业要求中,学科表要能处理学科代码的变更,如一级学科的编码长度变为 3 位。
由于学科分类的结构设计,在这种情况下,需要将该一级学科下的各级学科的编码都进行相应的调整,以确保数据的一致性和完整性。
因此,将学科信息的储存设计为嵌套结构,每个数据行都有 parent_id 列,指向上级学科的 id。
这样使得一级学科下的二级学科、三级学科等都可以在同一表中进行存储。更新时,只需更新一级学科的编码,其下的各级学科编码可通过触发器进行自动更新,确保了数据的完整性和一致性。查询时,只需将 parent_id 列与 self_id 列进行连接,即可得到完整且准确的学科编码。
可追溯的数据变更
由于上述原因,学科编码的变更需要有明确的可追溯性,以便于在查询时能够准确地找到对应的学科信息。
因此,在数据表中设计了每条记录的生效时间和失效时间,失效时间设为 NULL 时表示截止当前有效;同时,所有的数据更改都以 INSERT 的方式记录,所有历史数据都以数据行的形式保存在表中,避免数据丢失。
在这样的设计下,需要进行查询时,可通过学生的毕业时间对数据行的生效时间和失效时间进行筛选,从而来确定使用的学科编码,以确保数据准确无误。
示例数据说明
在本次作业中,为方便实验与说明,设计以下测试数据:
| |
在测试数据中,假设发生了以下变更事件:
- 2009 年 8 月 31 日,学科编号发生变更,计算机软件与理论 的编码由 081202 变更为 081204,其原编号 081202 分配给了新增的学科 软件工程 。
- 2014 年 1 月 1 日,学科大类编号发生变更,理学 的编码由 07 变更为 007,工学 的编码由 08 变更为 008,农学 的编码由 09 变更为 009 。
- 2018 年 1 月 1 日,计算机软件与理论 这个学科停用。新增了四级学科 嵌入式软件系统架构 ,其编码为 008120201 。
在下面的设计与测试中,将以此数据为基础进行学科编码的查询与验证。
触发器更新逻辑设计
为了实现学科编码和过期信息的自动更新,设计了一个触发器 update_subject_id,用于在插入新数据时自动更新下级学科的编码和过期信息。
该触发器会在插入新数据后,检查下级学科的编码,并根据需要进行更新;同时在插入新数据时,将原先可能有的旧数据标记为过期。
| |
在这个触发器对学科编码更改的处理逻辑中,由于对数据表进行了下一级学科的插入操作,于是触发器会被递归触发,以确保所有下级学科的编码都能得到更新。
查询逻辑设计
为了方便针对特定时间节点进行学科编码的查询,设计了一个函数 subject_full_id,用于根据时间节点查询拼接后的完整学科编码。该函数将根据输入的时间参数,结合 start_date 和 end_date 字段,返回对应的学科编码。
| |
创建这个函数后,可以通过调用 subject_full_id 函数来查询特定时间节点的学科编码。
例如,查询 2010 年 8 月 31 日的学科编码,可以使用以下 SQL 语句:
| |
查询结果如下:
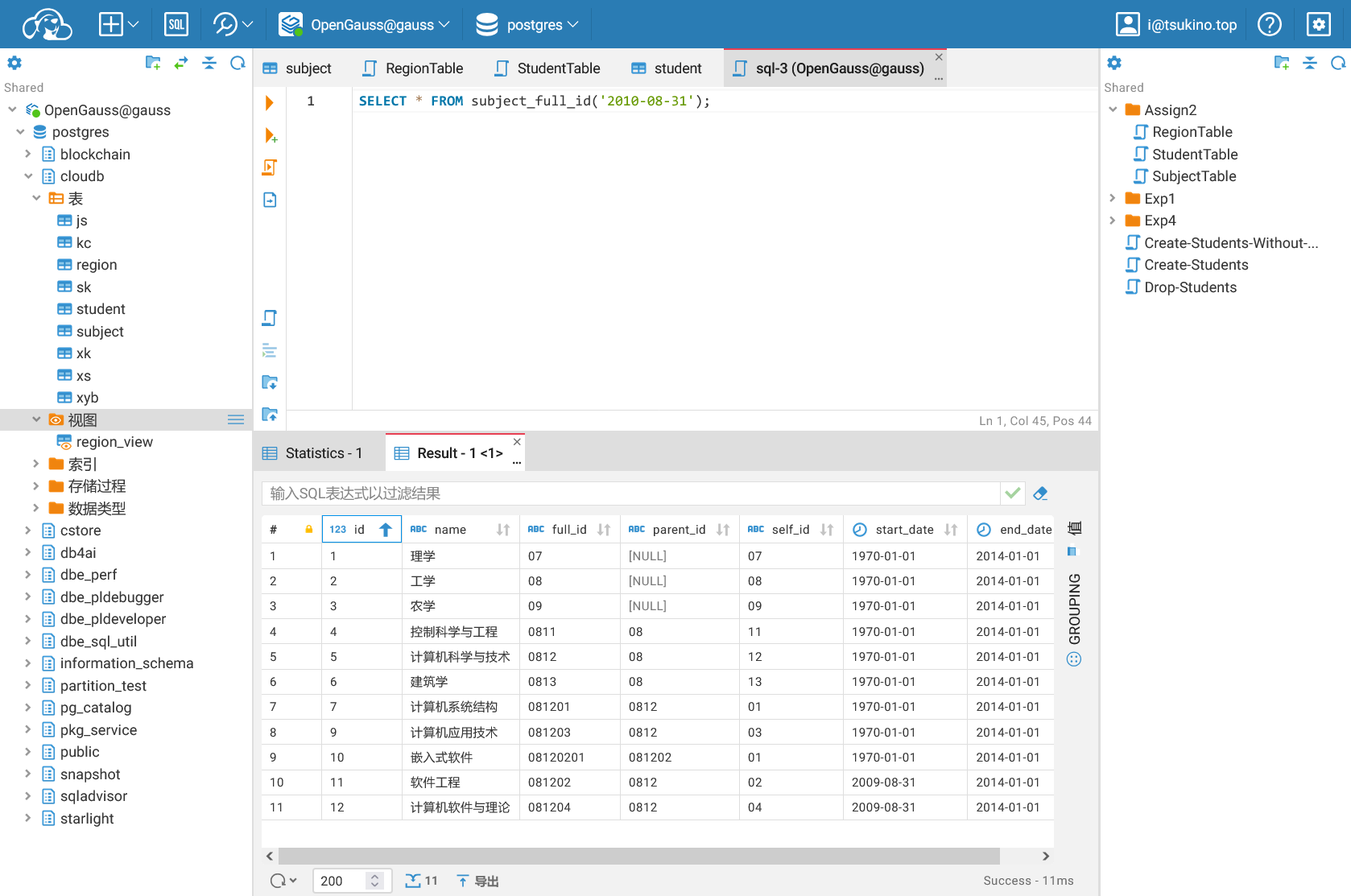
再进行 2016 年 8 月 31 日的学科编码查询,结果如下:
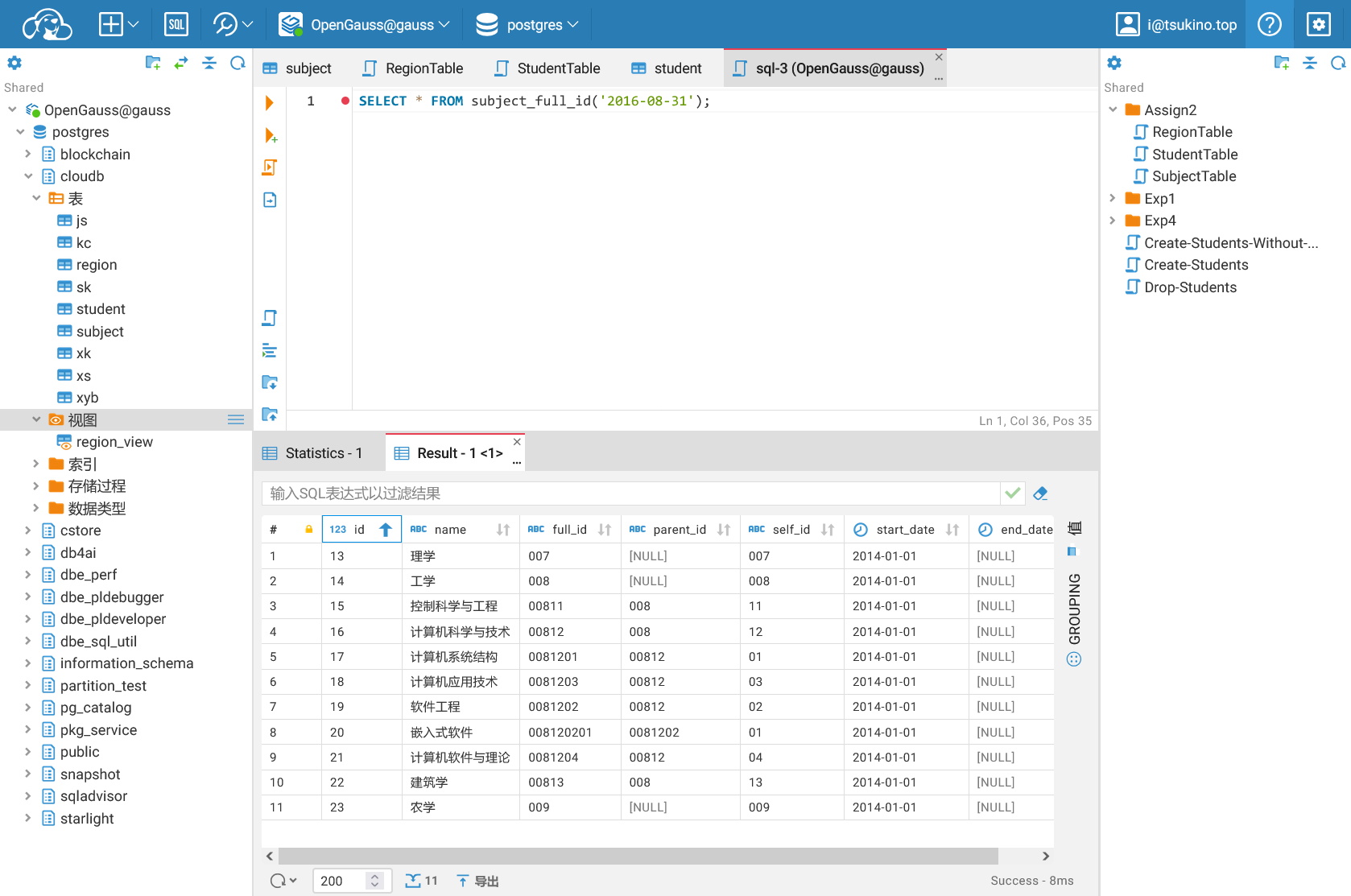
可以看见,在我们的学科编号数据中,由于 2014 年学科大类编号从 2 位变为了 3 位,导致了在后续的时间点进行查询时,各个学科的编号和生效时间、失效时间都发生了相对应的变化。
再对 2018 年 6 月 1 日的学科编码进行查询,结果如下:
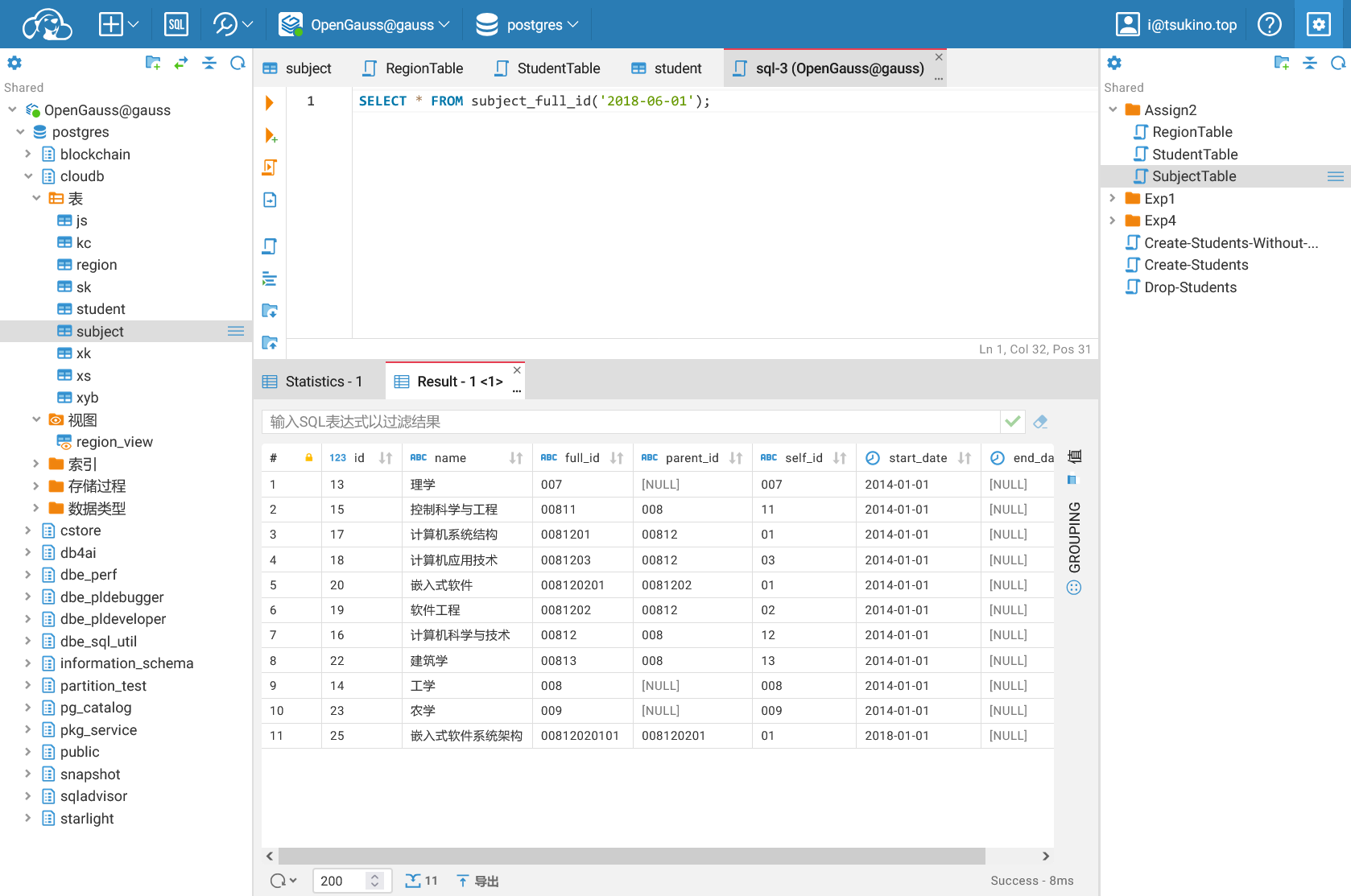
可以看见,由于 2018 年 1 月 1 日发生的变化,在后续的时间点进行查询时,各个学科的数据行也都发生了相对应的变化。
设计籍贯表
储存学生个人信息时,籍贯信息是经常设计的一部分。但由于我国在过去数十年间,对行政区划进行了大量的调整,导致了籍贯信息的设计需要不断更新和调整,以确保其准确性和有效性。
为确保籍贯信息的准确性,设计了籍贯信息表,以便及时反映行政区划的变化。该表将包含各个地区的名称、编码、以及地区的变更信息,以支持对籍贯信息的动态管理和查询。
数据表的设计如下:
| |
其中,id 列储存的是符合我国居民身份证号中地区信息编码规则的六位编码,如:110101 表示北京市东城区。replaced_by 列储存的是变更后的编号,例如,在重庆市从四川省脱离,成为直辖市时,原编码 510200 的 replaced_by 列将被更新为新的编码 500100。此时进行查询,不论是使用 510200 还是 500100 ,查询到的地区名称都将是 重庆市 而非过时的 四川省重庆市。
插入的数据如下:
| |
为方便查询,可以创建视图以简化查询过程。创建视图的 SQL 语句如下:
| |
可以看到,视图 region_view 通过 JOIN 进行列的连接,显示所有地区的现行名称和编号。通过使用 COALESCE 函数,可以确保即使在没有变更的情况下,查询结果也能正确显示地区名称。
对视图进行查询,结果如下:
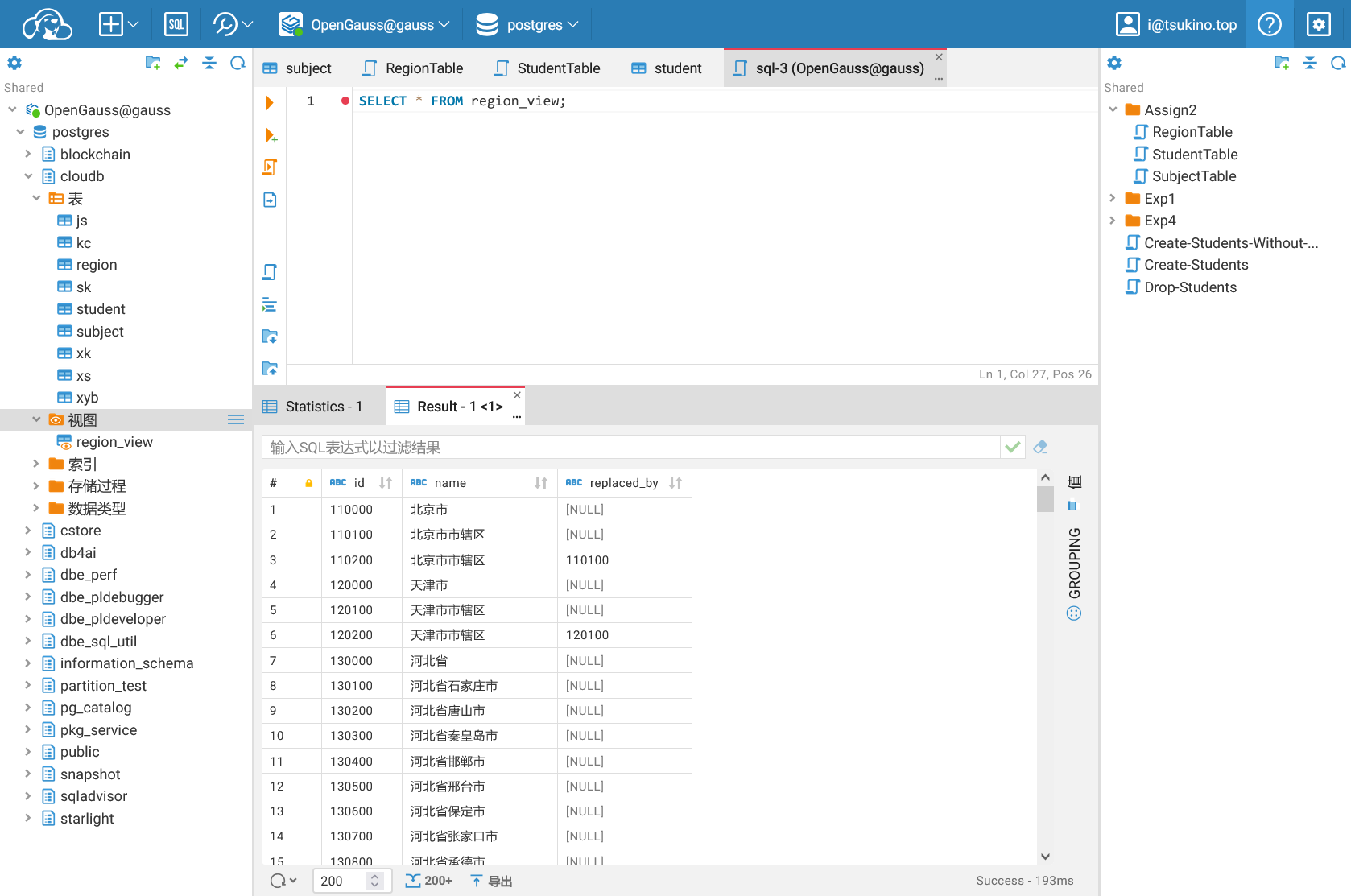
设计学生表
为了储存学生信息,学生表格设计如下:
| |
插入以下测试用例数据:
| |
查询学生信息
为方便查询全部学生的信息,设计了查询函数如下:
| |
执行查询函数时,使用如下语句:
| |
查询结果如下:
| id | name | graduate_date | region_name | region_id | subject_name | subject_id |
|---|---|---|---|---|---|---|
| 1120090001 | 张三 | 2013-06-30 | 北京市市辖区 | 110100 | 计算机应用技术 | 081203 |
| 1120090002 | 李四 | 2013-06-30 | 重庆市 | 510200 | 软件工程 | 081202 |
| 1120090003 | 王五 | 2013-06-30 | 湖北省荆州市 | 420400 | 计算机系统结构 | 081201 |
| 1120090004 | 赵六 | 2013-06-30 | 西藏自治区日喀则市 | 542300 | 软件工程 | 081202 |
| 1120000001 | 刘七 | 2004-06-30 | 北京市市辖区 | 110100 | 计算机应用技术 | 081203 |
| 1120000002 | 朱八 | 2004-06-30 | 重庆市 | 510200 | 计算机软件与理论 | 081202 |
| 1120000003 | 徐九 | 2004-06-30 | 湖北省荆州市 | 420400 | 计算机系统结构 | 081201 |
| 1120000004 | 吴十 | 2004-06-30 | 西藏自治区日喀则市 | 542300 | 计算机软件与理论 | 081202 |
| 1120150001 | 钱十一 | 2019-06-30 | 北京市市辖区 | 110100 | 计算机应用技术 | 0081203 |
| 1120150002 | 孙十二 | 2019-06-30 | 重庆市市辖区 | 500100 | 计算机系统结构 | 0081201 |
| 1120150003 | 周十三 | 2019-06-30 | 湖北省荆州市 | 421000 | 计算机系统结构 | 0081201 |
| 1120150004 | 郑十四 | 2019-06-30 | 西藏自治区日喀则市 | 540200 | 计算机应用技术 | 0081203 |
| 1120240001 | 林十五 | NULL | 上海市市辖区 | 310100 | 计算机系统结构 | 0081201 |
可以看见,查询结果中根据学生的毕业日期,查询到了毕业时学科编号所对应的学科名称;而学生的籍贯信息显示的是当前的区域名称。
例如,学生 朱八 于 2004 年毕业时,其学科编号 081202 所对应的学科为 计算机软件与理论 而不是软件工程;虽然其籍贯信息为旧 四川省重庆市 的编号,显示其籍贯仍为 重庆市。
修改学生专业信息
由于只有在校生有可能修改其专业信息,因此设计了如下函数:
| |
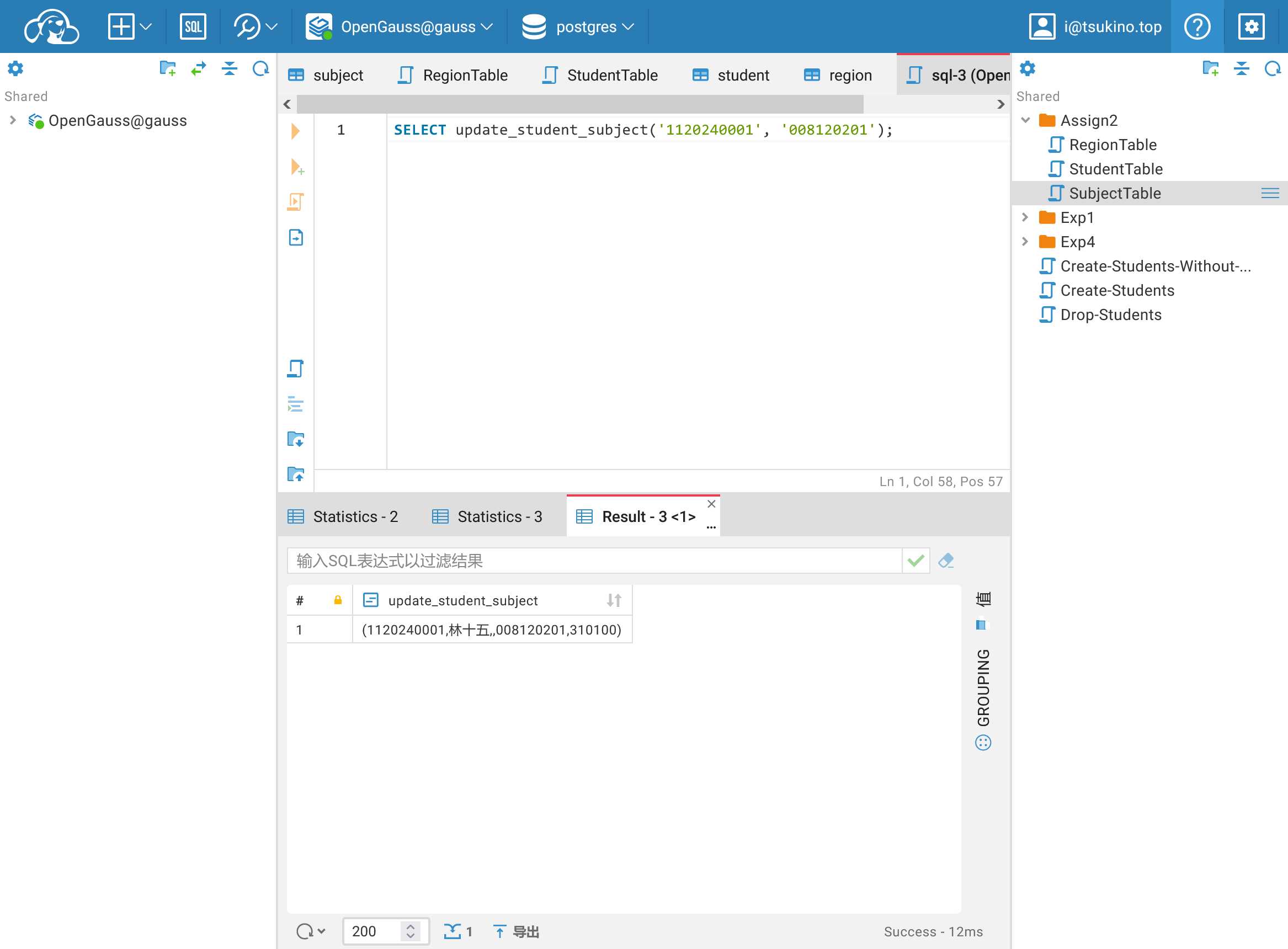
添加函数之后,可以使用如下语句修改学生 林十五 的专业信息为嵌入式软件系统架构:
| |
设计成绩表
为进行学生成绩的储存与查询,设计学生成绩表如下:
| |
该表格使用外键约束来确保学生ID的有效性;使用由学生ID和科目名称组成复合主键,以确保每个学生在每个科目上只能有一条成绩记录。
插入以下测试用例数据:
| |
查询成绩表
使用连接语句进行成绩表的查询:
| |
实现交叉表查询
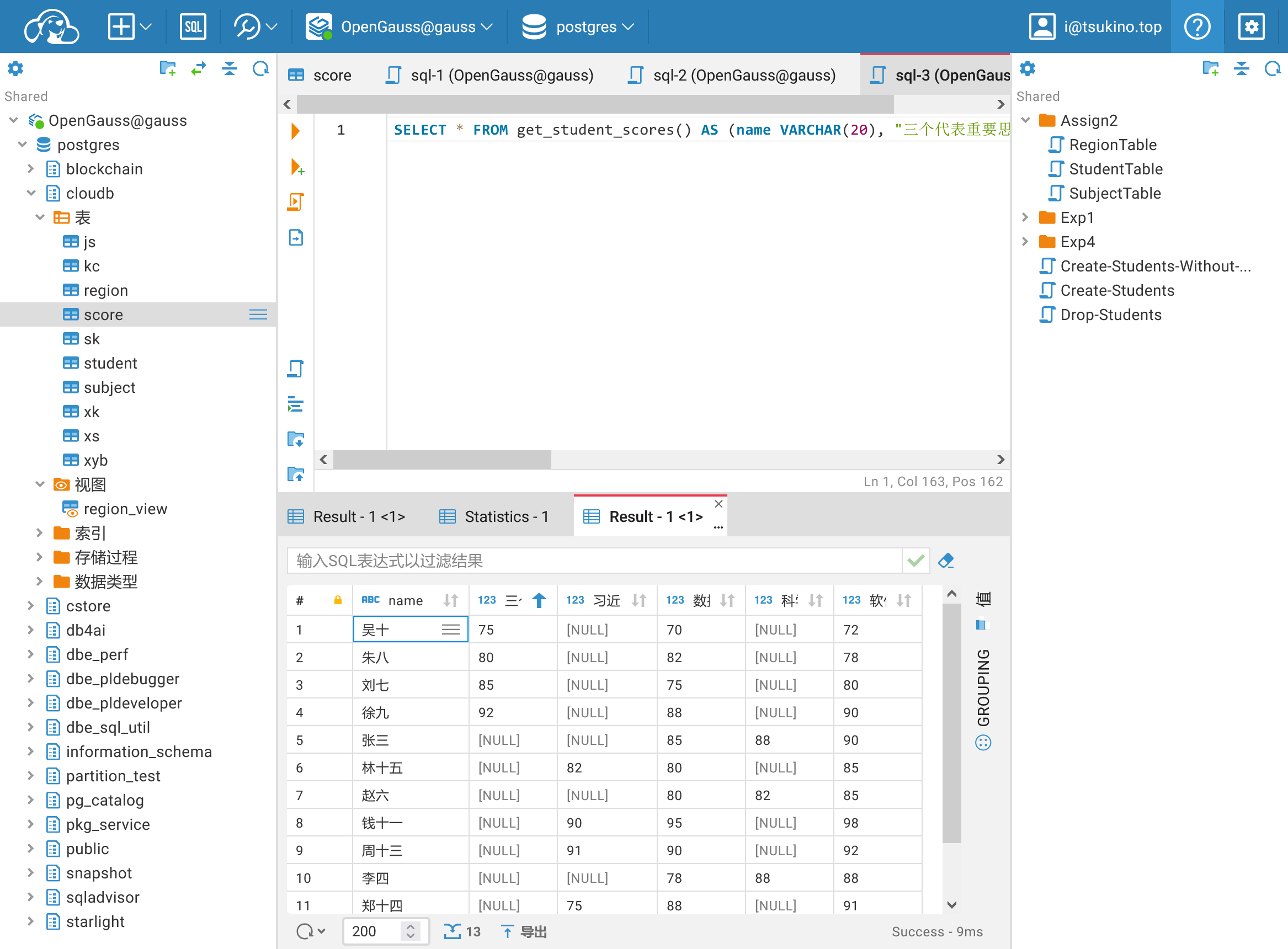
为了使成绩查询更加直观,可以使用交叉表的思想,将成绩表转换为以下形式:
| 姓名 | 三个代表重要思想 | 习近平新时代中国特色社会主义思想概论 | 数据库设计与开发 | 科学发展观 | 软件工程导论 |
|---|---|---|---|---|---|
| 李四 | NULL | NULL | 78.00 | 88.00 | 88.00 |
| … | … | … | … | … | … |
这可以通过以下 SQL 语句实现:
| |
要进行查询,需要先对动态的列名称进行查询,可使用这个 DO 块来动态生成最终的 SQL 查询语句:
| |
执行这个 DO 块后,将会输出动态生成的 SQL 查询语句,在本次作业的示例数据中,结果为:
| |
查询结果如下:
总结与体会
在这次作业中,通过设计和实现一个教学系统的数据库,深入理解了数据库设计中的几个重要概念:
数据的时效性
设计学科表和籍贯表时,都需要考虑数据的时效性问题。例如:
- 学科代码随时间变化,同一编码在不同时期可能对应不同学科
- 行政区划调整导致籍贯信息变化,如重庆从四川省独立
我们通过以下方式解决这些问题:
- 使用生效时间和失效时间记录数据的有效期
- 使用
replaced_by字段记录替换关系 - 保留历史记录而不是直接更新
数据的层次结构
在设计学科表时,需要处理复杂的层次结构:
- 学科编码具有固定的层次含义(一级、二级等)
- 编码的层级数量可能发生变化(如增加四级学科)
- 编码的长度也可能变化(如从2位变为3位)
解决思路:
- 使用递归结构储存层级关系
- 设计触发器自动处理下级编码的更新
- 通过视图简化对层次结构的查询
数据的一致性
在处理数据变更时,需要特别注意数据的一致性:
- 学生毕业后的专业信息不应随学科代码变更而改变
- 但籍贯信息应随行政区划变更而更新
- 成绩记录需要与学生信息保持关联
采取的措施:
- 使用外键约束确保数据引用的正确性
- 设计查询函数自动处理时间相关的版本选择
- 通过视图屏蔽底层数据的复杂性
实用性思考
此次设计中还有一些值得思考的实用性问题:
- 数据表的设计需要在完整性和效率之间取舍
- 触发器的使用需要考虑性能影响
- 交叉表查询的实现需要考虑动态性和可扩展性