实验任务
- 使用 PuTTY 和 Data Studio 连接Gauss数据库
- 通过连接工具使用 SQL 建立数据库
- 执行数据库查询
- 使用“
INSERT”语句向主表插入至少5行数据,向子表插入至少30行数据; - 在子表中输入含有不存在外键值的数据;
- 观察数据库系统的反应
- 使用
SELECT * FROM ...观察数据; - 使用所有学习的查询语句对表格的进行查询(自拟题目);
- 更新部分学生的学籍情况、成绩;
- 删除部分同学的学籍信息;
实验过程
连接到数据库
使用 PuTTY 连接到 OpenGauss 数据库
PuTTY 是一个免费的 SSH、Telnet 和 Rlogin 客户端,适用于 Windows 和 Unix 平台,提供多种功能,包括:
- 远程连接:通过 SSH 协议安全地连接到远程服务器。
- 终端仿真:模拟各种终端类型,如 xterm、vt102 等。
由于微软在 Windows 内置了 Windows Terminal 这一工具, 其功能与 PuTTY 类型,因此本次实验使用 Windows Terminal 和 OpenSSL 提供的 SSH 客户端连接到 OpenGauss 数据库。
使用 SSH 连接到服务器时,通常需要提供用户名和密码。由于先前设置了 SSH 密钥对,因此可以使用 SSH 密钥进行身份验证,而无需输入密码。
登录之后, 切换到 omm 用户, 使用命令 gs_ctl status 查看数据库状态, 如果数据库未启动, 使用命令 gs_ctl start 启动数据库.
数据库启动后, 使用 psql -d postgres 命令连接到 OpenGauss 数据库中的 postgres 数据库.
使用 Data Studio 连接到 OpenGauss 数据库
Data Studio 是华为推出的一款数据库开发和管理工具,旨在简化数据库的开发、管理和维护工作。它提供了一个集成的开发环境,支持多种数据库类型,并提供了丰富的功能,如数据建模、SQL 开发、数据迁移、性能诊断等。
- 多数据库支持: 支持连接和管理多种数据库,包括 MySQL, PostgreSQL, SQL Server, Oracle, DB2, 华为云 GaussDB 等。
- 数据建模: 提供图形化的数据建模工具,方便用户设计和管理数据库结构。
- SQL 开发: 提供强大的 SQL 编辑器,支持语法高亮、自动完成、调试等功能,提高 SQL 开发效率。
- 数据迁移: 支持不同数据库之间的数据迁移,简化数据迁移过程。
- 性能诊断: 提供数据库性能诊断工具,帮助用户发现和解决数据库性能问题。
- 用户界面: 提供直观的用户界面,易于上手和使用。
从华为云官网上下载 Data Studio 的安装包,安装完成后打开 Data Studio,点击左上角的“新建连接”按钮,选择 GaussDB 数据库类型,输入连接信息,包括主机名、端口号、用户名和密码等。点击“测试连接”按钮,确保连接成功后,点击“确定”按钮保存连接信息。
连接到数据库后, 在左侧的数据库导航栏中可以看到连接的数据库,点击数据库名称展开数据库对象列表,包括表、视图、存储过程等。右键点击表名,选择“查看数据”选项,可以查看表中的数据。
使用 Cloudbeaver 连接到 OpenGauss 数据库
Cloudbeaver 是一个基于 Web 的数据库管理工具,它提供了一个图形化的用户界面,用于访问、管理和分析各种类型的数据库。
- 跨平台: Cloudbeaver 可以在任何支持 Web 浏览器的操作系统上运行。
- 多数据库支持: Cloudbeaver 支持 JDBC 连接, 因此支持包括 MySQL, PostgreSQL, MariaDB, SQL Server, Oracle, DB2, OpenGauss 等多种数据库。
- Web界面: 通过 Web 界面进行数据库管理,无需安装客户端。
- 数据浏览与编辑: 允许用户浏览数据库中的表、视图、存储过程等对象,并进行数据的编辑。
- SQL编辑器: 提供 SQL 编辑器,支持语法高亮、自动补全等功能。
- 数据导出: 支持将数据导出为多种格式,如 CSV, Excel, JSON 等。
Cloudbeaver 适用于需要通过 Web 界面管理数据库的场景,例如:
- 远程数据库管理
- 团队协作开发
- 云环境下的数据库管理
由于 Cloudbeaver 支持使用 JDBC 插件连接到数据库,因此可以使用华为官方提供的 JDBC 插件连接到 OpenGauss 数据库。
将 OpenGauss 的 JDBC 驱动程序放入 Cloudbeaver 的 Docker 镜像中, 以便在 Docker 中容器化部署服务。
使用 Docker Compose 部署 Cloudbeaver, docker-compose.yml 文件如下:
| |
使用 docker-compose up -d 命令启动 Cloudbeaver 服务, 在浏览器中打开页面, 配置 OpenGauss 数据库的登录账号和密码, 连接到数据库。
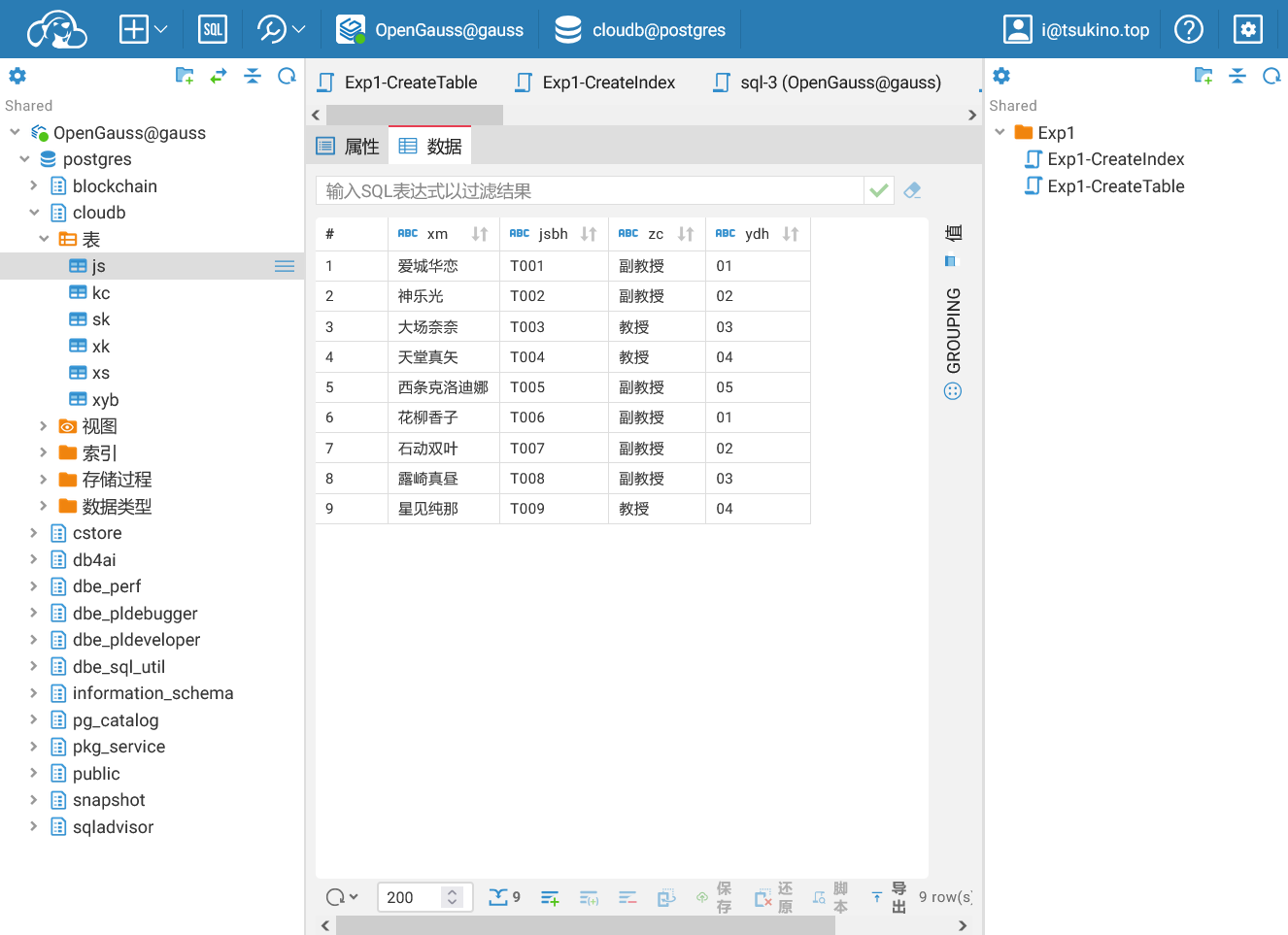
建立数据库
建立数据表
在实验一中, 根据实验要求,设计了“学籍与成绩管理系统”中的一系列表格. 创建表格的SQL语句如下:
| |
使用Data Studio连接到数据库后, 执行上述SQL语句创建表格. SQL语句运行成功后, 可从Data Studio左侧的数据库树中查看到创建的表格.
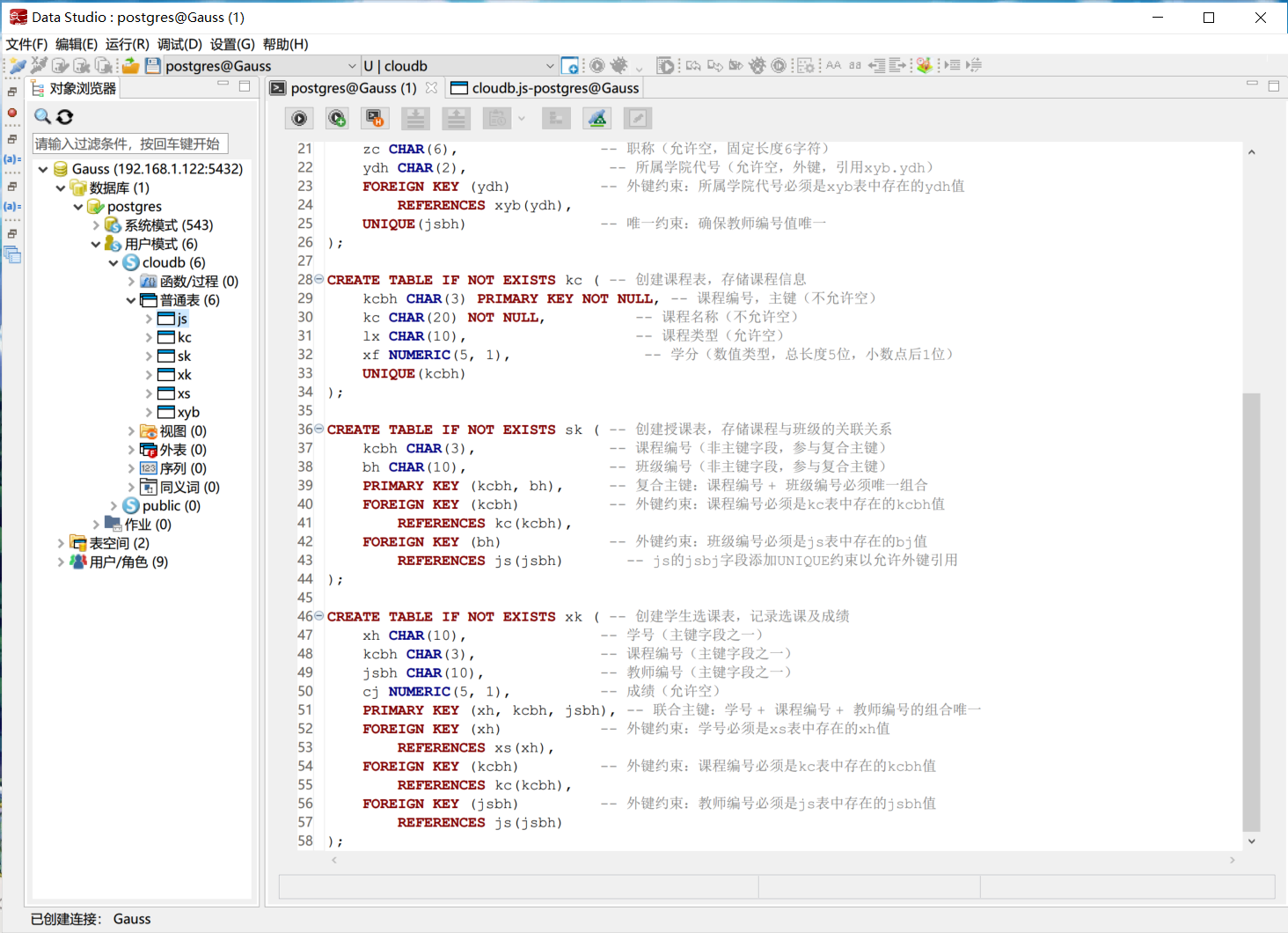
建立索引
建立数据表之后, 根据数据特点, 针对部分常用的查询进行索引设计, 以提高查询效率. 例如, 在学生表的学号字段上建立索引, 在课程表的课程编号字段上建立索引, 在教师表的教师编号字段上建立索引, 在选课表的学号和课程编号字段上建立联合索引等.
| |
在Data Studio中运行上述SQL语句, 可在左侧的数据库树中查看到创建的索引. 右键点击表格, 选择“查看索引”即可查看到创建的索引.
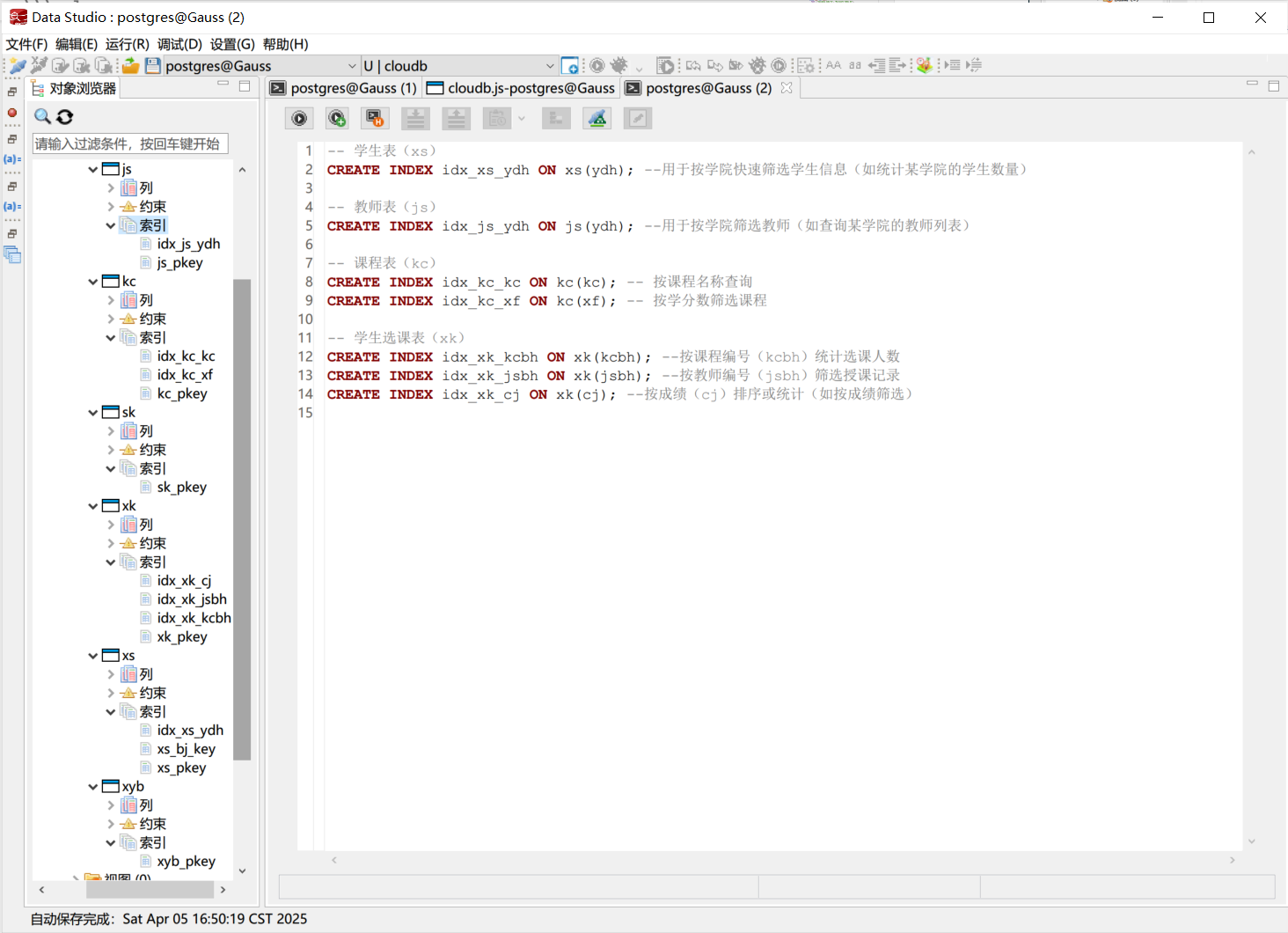
插入数据
根据实验要求, 向主表插入至少5行数据, 向子表插入至少30行数据. 具体的SQL语句如下:
| |
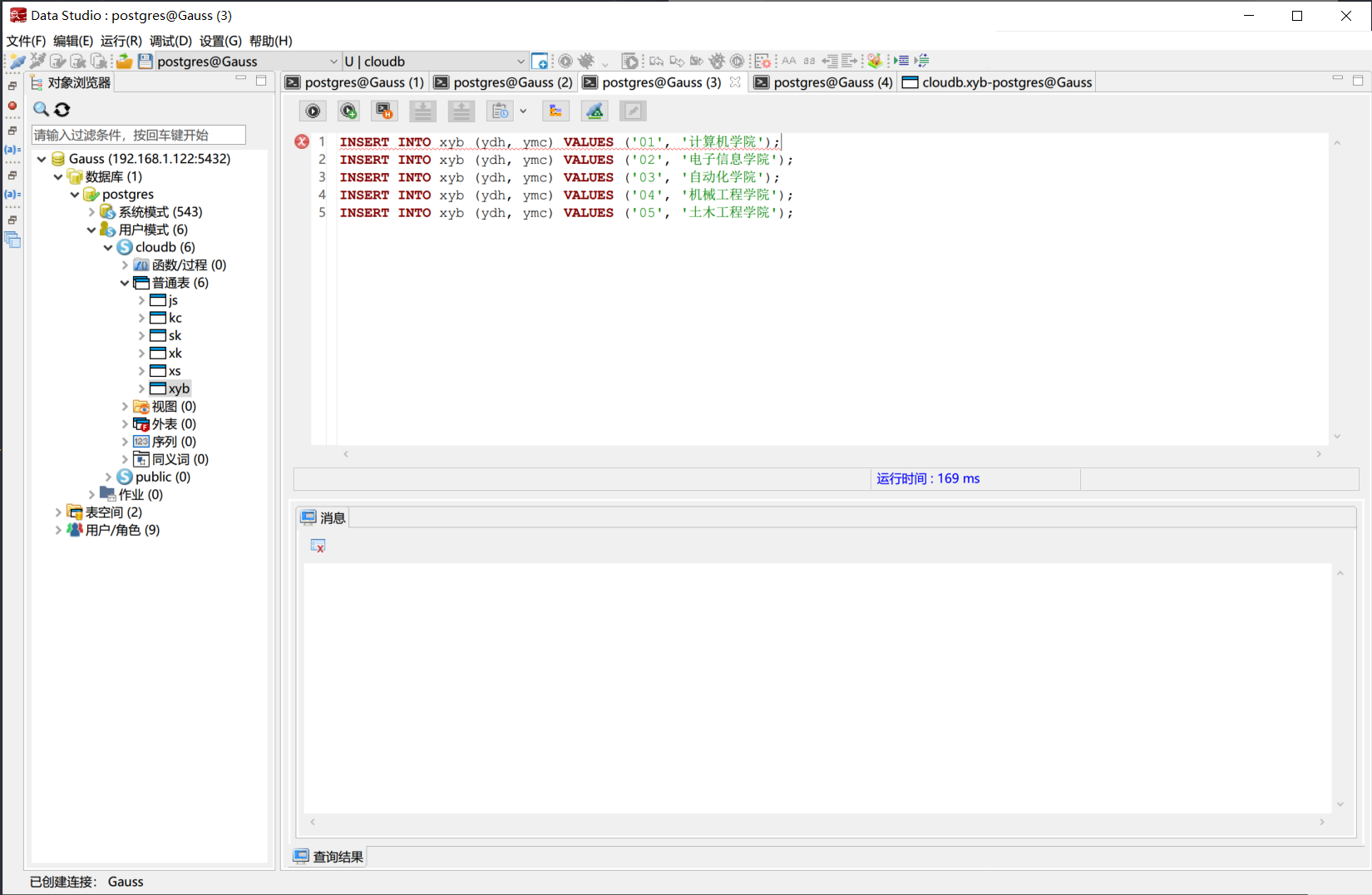
输入含有不存在外键值的数据
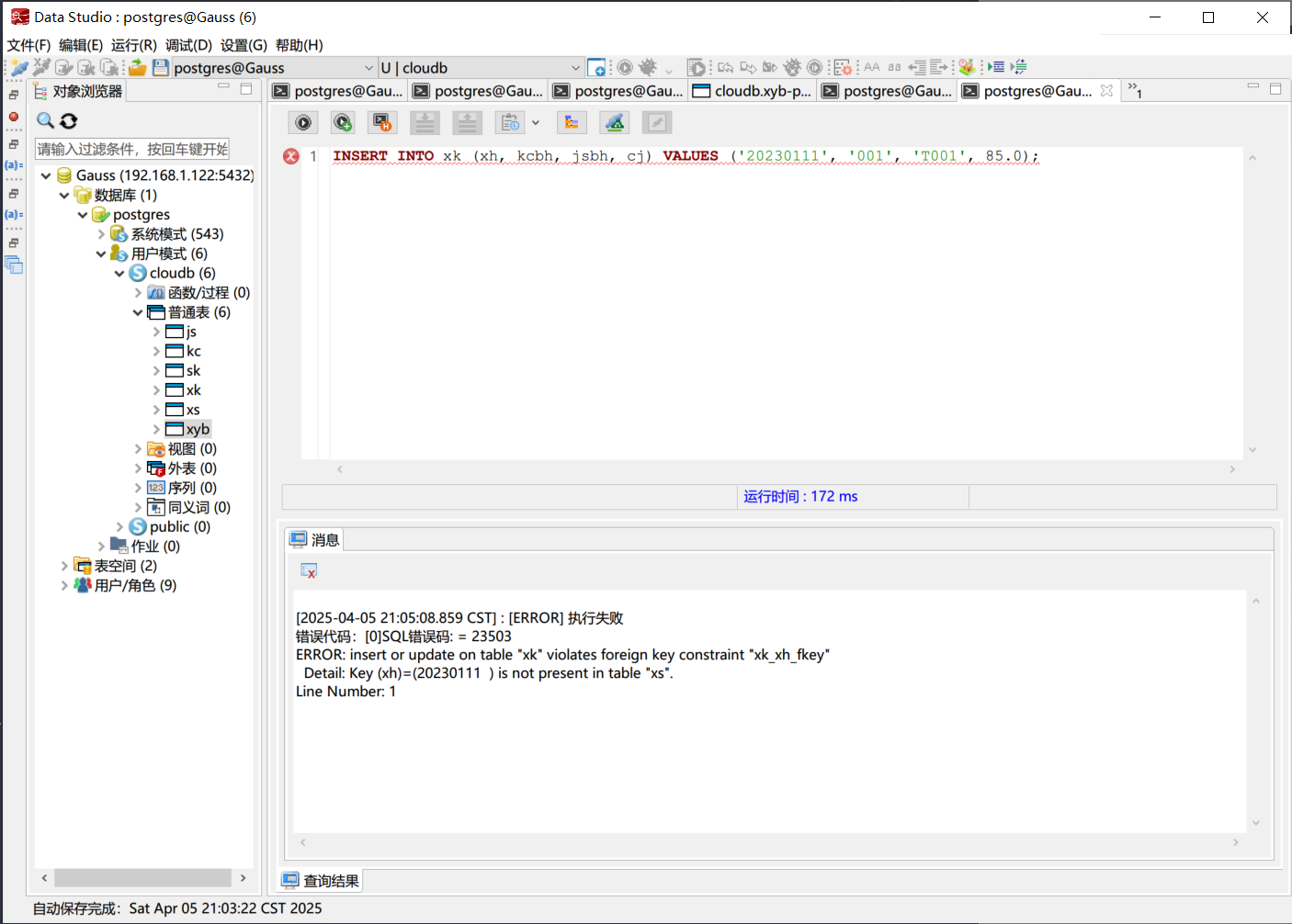
在选课表中输入含有不存在外键值的数据, 例如, 插入一条学号为“20230111”的学生选课记录, 但该学号在学生表中并不存在. 执行以下SQL语句:
| |
执行该SQL语句后, 数据库系统会报错, 提示外键约束失败. 这是因为在选课表中插入的学号“20230111”在学生表中并不存在, 导致外键约束失败.
但是如果插入的数据中, 有外键约束的列为NULL, 则不会报错. 例如, 插入一条学生记录, 但学院代号为NULL, 即不指定学院. 执行以下SQL语句:
| |
执行该SQL语句后, 数据库会成功插入数据. 这是因为在学生表中, 学院代号ydh是允许为空的, 因此可以插入NULL值.
这说明了外键约束的作用是确保引用的完整性, 但允许NULL值的存在. 这在实际应用中是很常见的, 因为有些数据在插入时可能并不确定, 可以先插入NULL值, 后续再进行更新.
查询数据库
使用 SELECT * FROM ... 语句查询数据
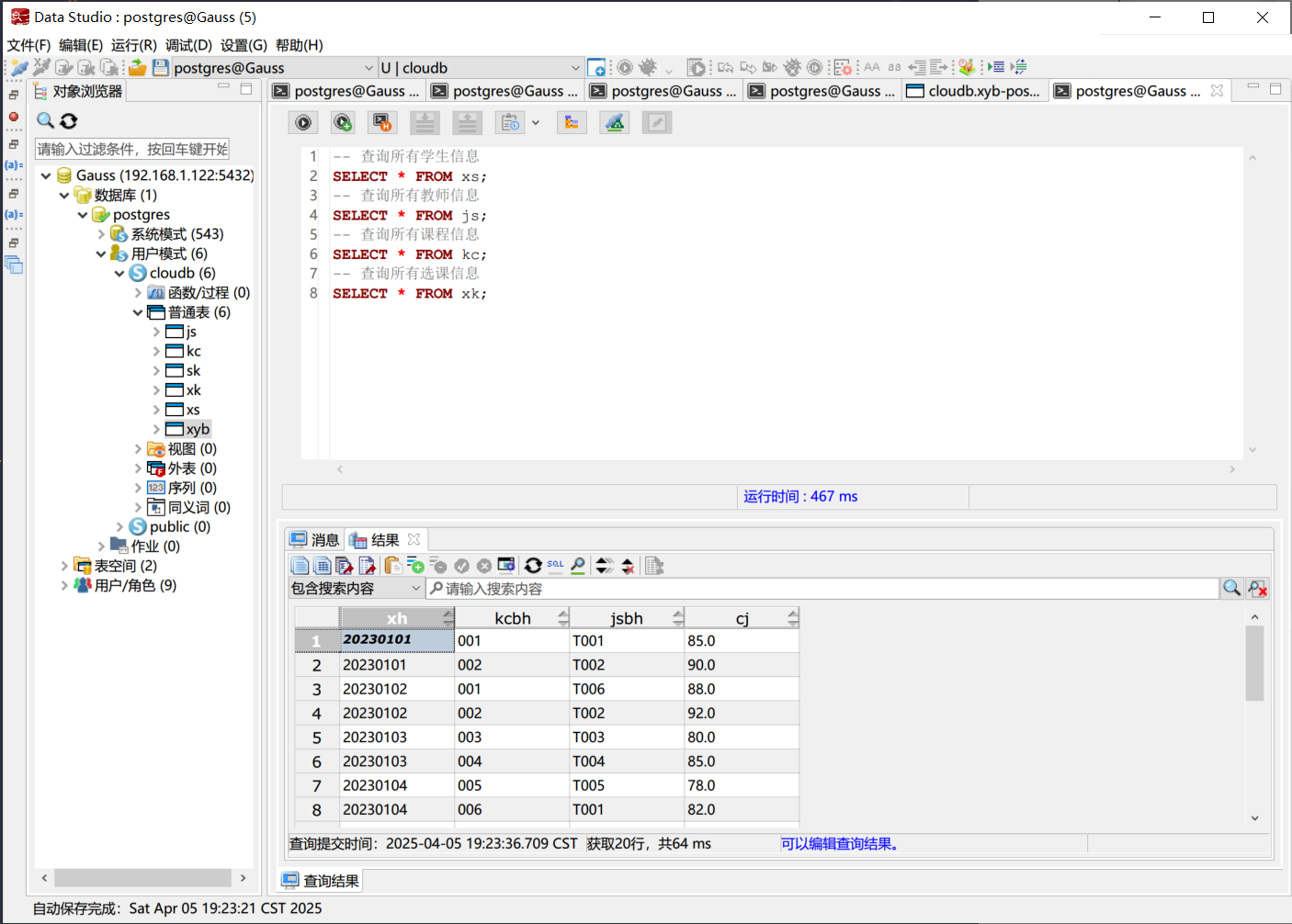
使用Data Studio连接到数据库后, 编写SQL语句查询数据. 例如, 查询所有学生信息, 查询所有教师信息, 查询所有课程信息, 查询所有选课信息等. 具体的SQL语句如下
| |
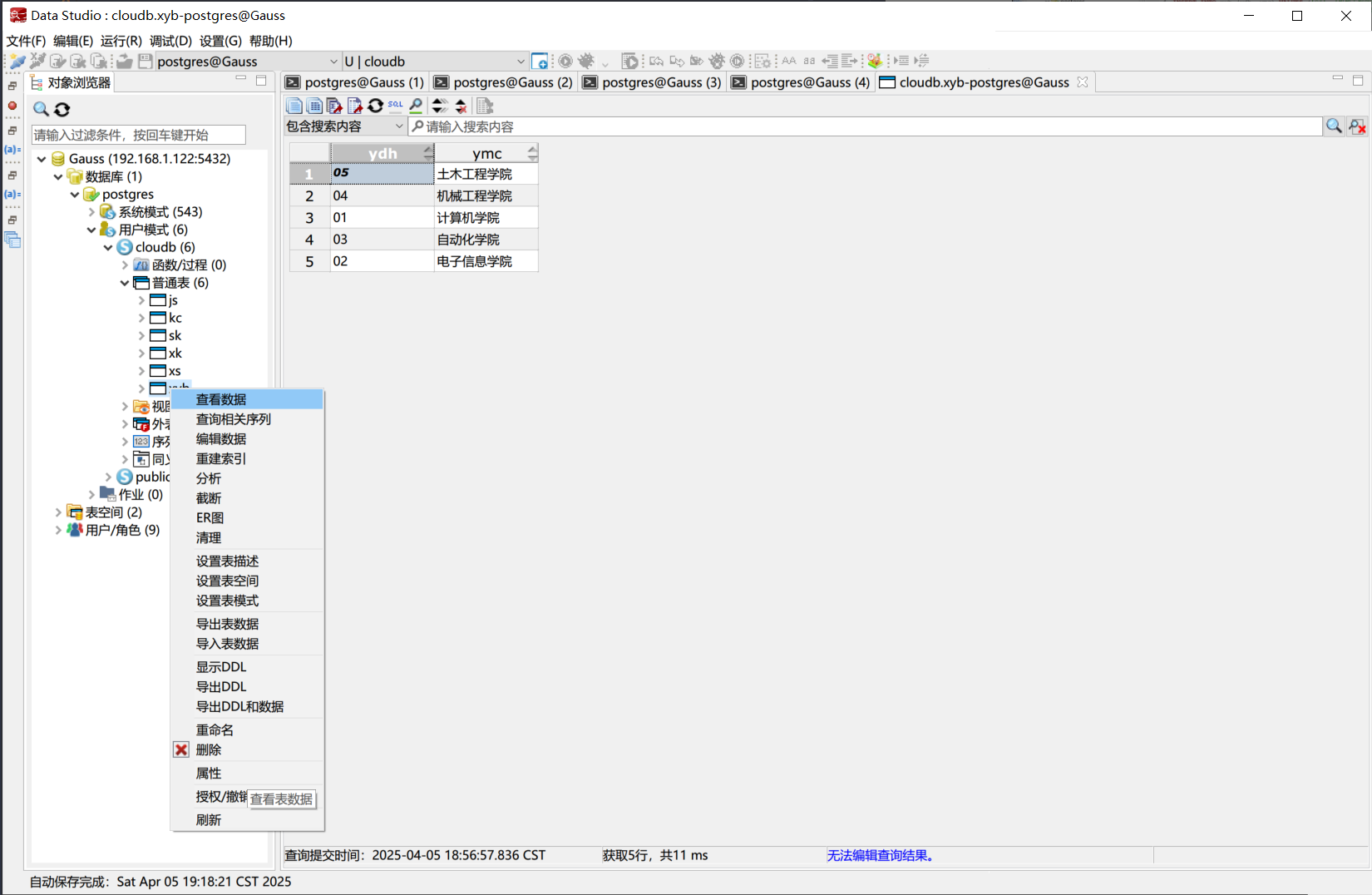
此外, 还可以使用 Data Studio 界面化查询数据. 在左侧的数据库树中, 右键点击表格, 选择“查看数据”, 即可查询表中数据.
自拟题目对表格进行查询
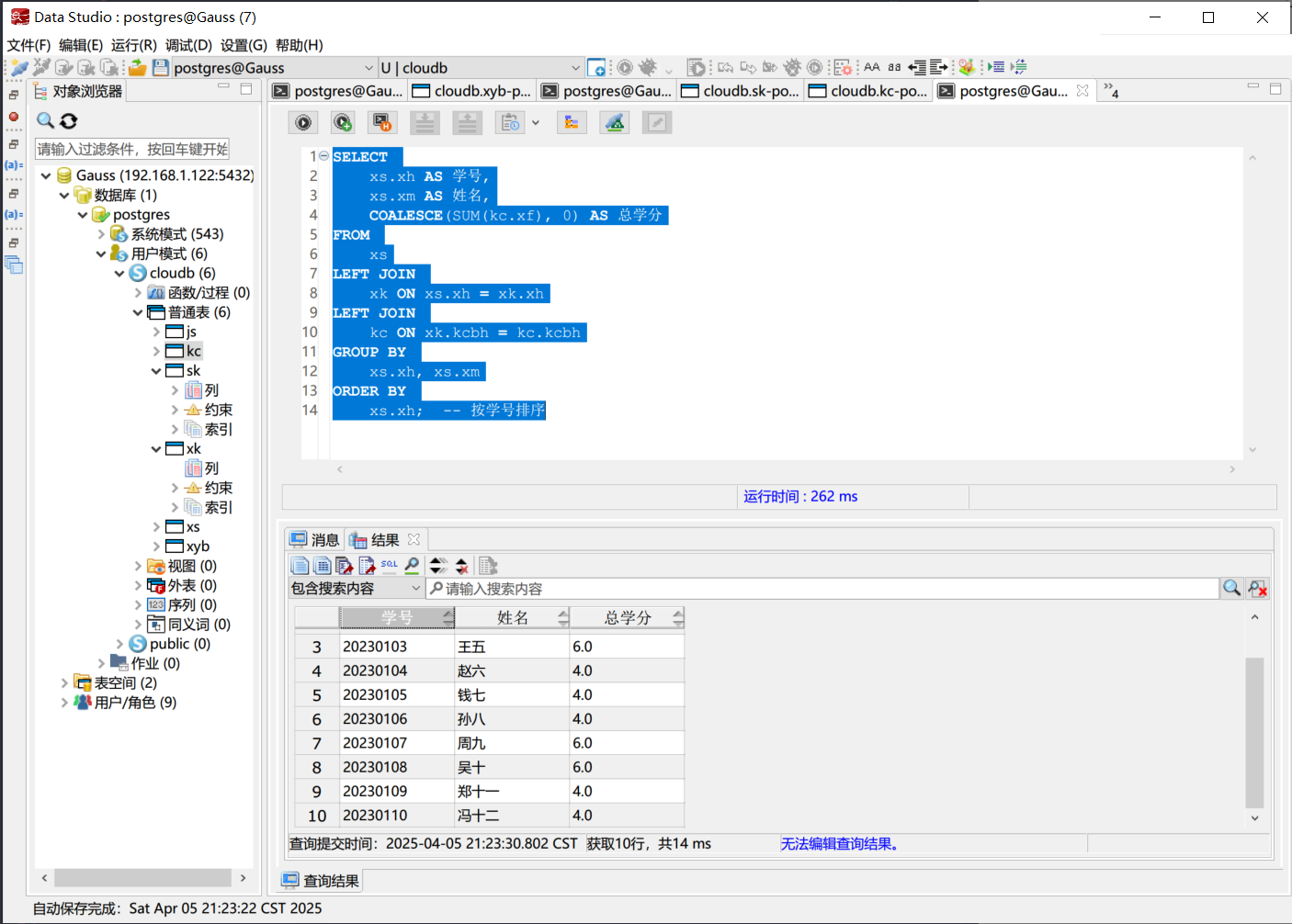
查询所有学生的学分
通过学生表与选课表关联,再通过选课表与课程表关联。使用 SUM(kc.xf) 对每个学生的课程学分求和。使用 LEFT JOIN 和 COALESCE() 确保即使学生未选课,也能显示总学分为 0。
| |
查询每个学生的平均分
通过学生表与选课表关联,再通过选课表与课程表关联。使用 AVG(xk.cj) 对每个学生的课程成绩求平均。使用 LEFT JOIN 和 COALESCE() 确保即使学生未选课,也能显示平均分为 0。
| |
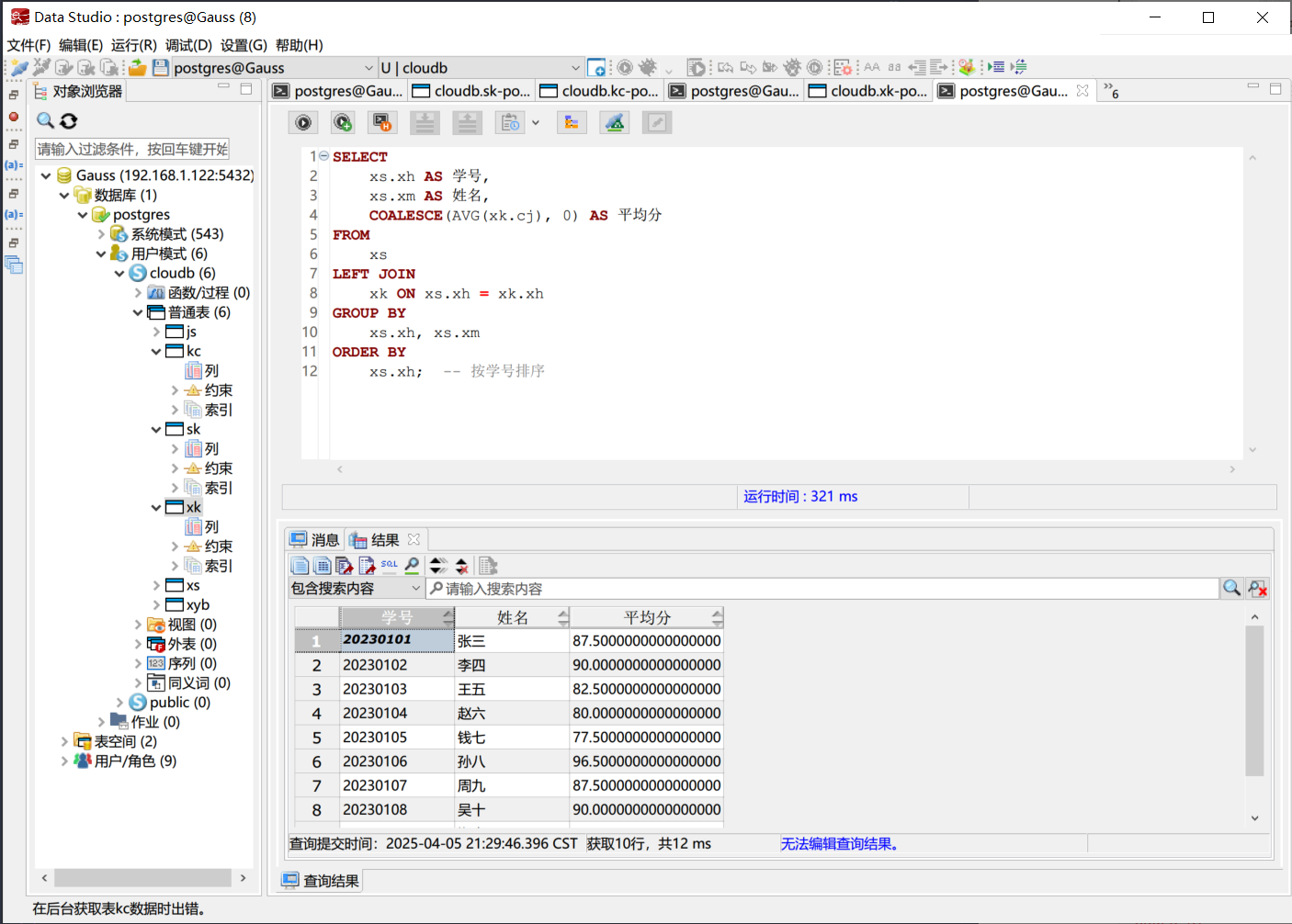
将学生按照选课数量降序排序
通过学生表与选课表关联。使用 COUNT(xk.kcbh) 统计每个学生的选课数量。使用 LEFT JOIN 和 COALESCE() 确保即使学生未选课,也能显示选课数量为 0。
| |
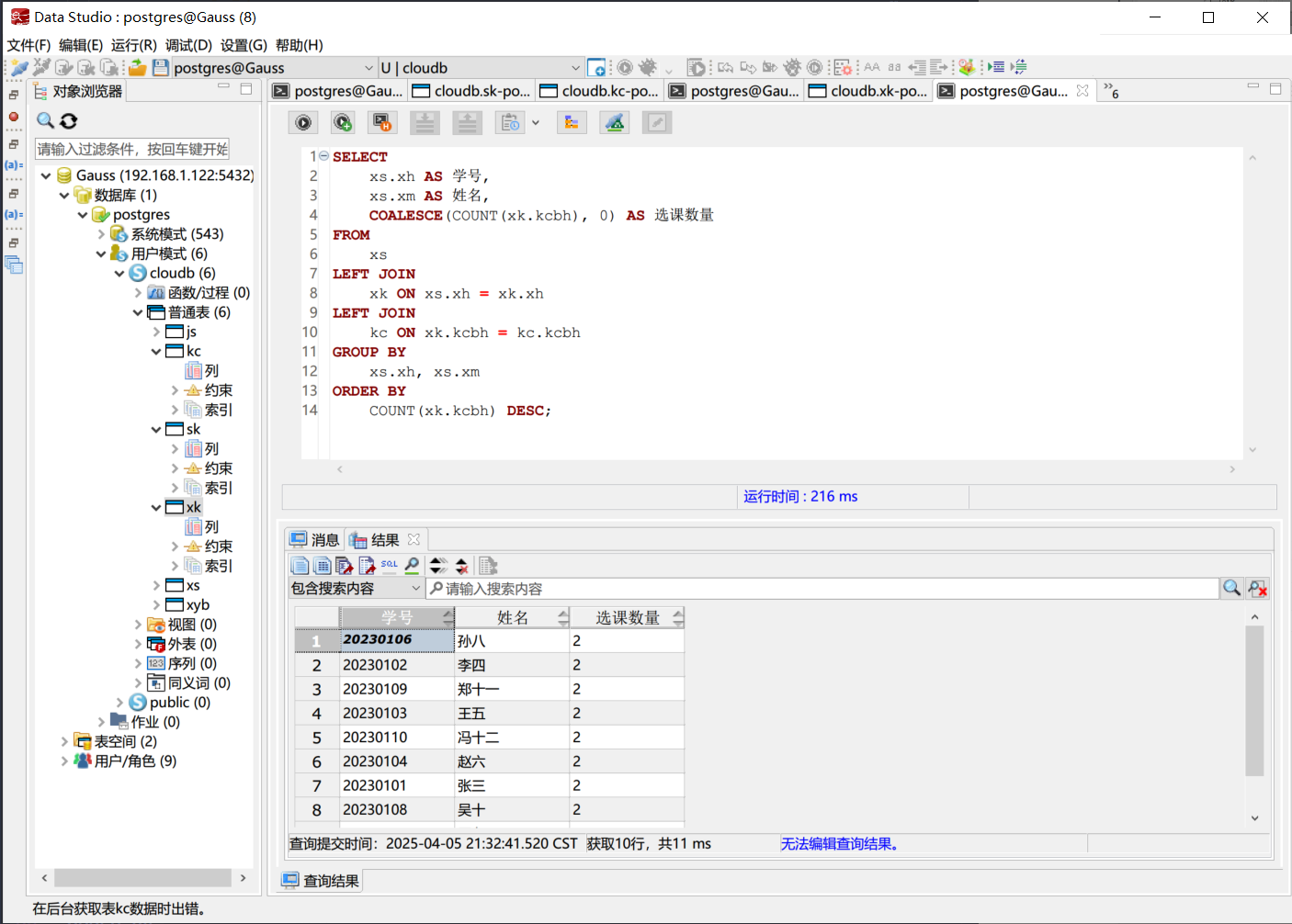
查询每个教师的授课数量与平均分
通过授课表统计每个教师的授课次数。
子查询 sk_count 统计每个教师在授课表中的记录数(即授课门数)。
使用 LEFT JOIN 确保即使教师未授课,也能显示 0。
通过选课表计算每个教师所教课程的学生平均成绩。
子查询 avg_cj 计算每个教师的平均分。
使用 ROUND(..., 1) 保留一位小数。
| |
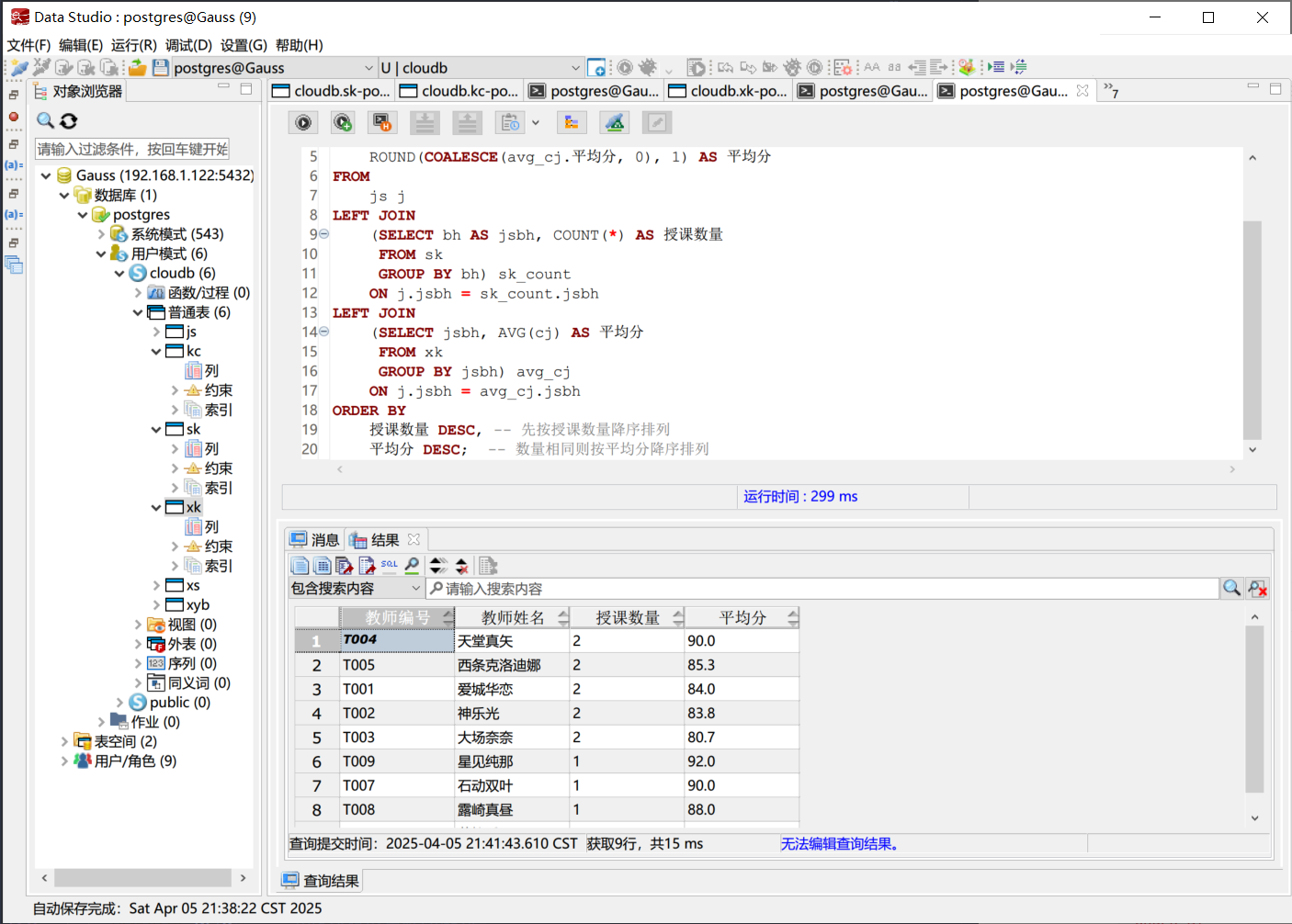
修改数据库数据
更新部分学生的学籍情况或成绩
使用 SQL 语句中的 UPDATE 语句更新学生的学籍情况或成绩。可以使用 SET 语句设置要更新的字段和新值。可以使用 WHERE 子句指定要更新的记录。
例如, 将学号为 20230102 的学生的专业更新为 计算机科学与技术,将学号为 20230104 的学生 006 课程的成绩更新为 90.0。
| |
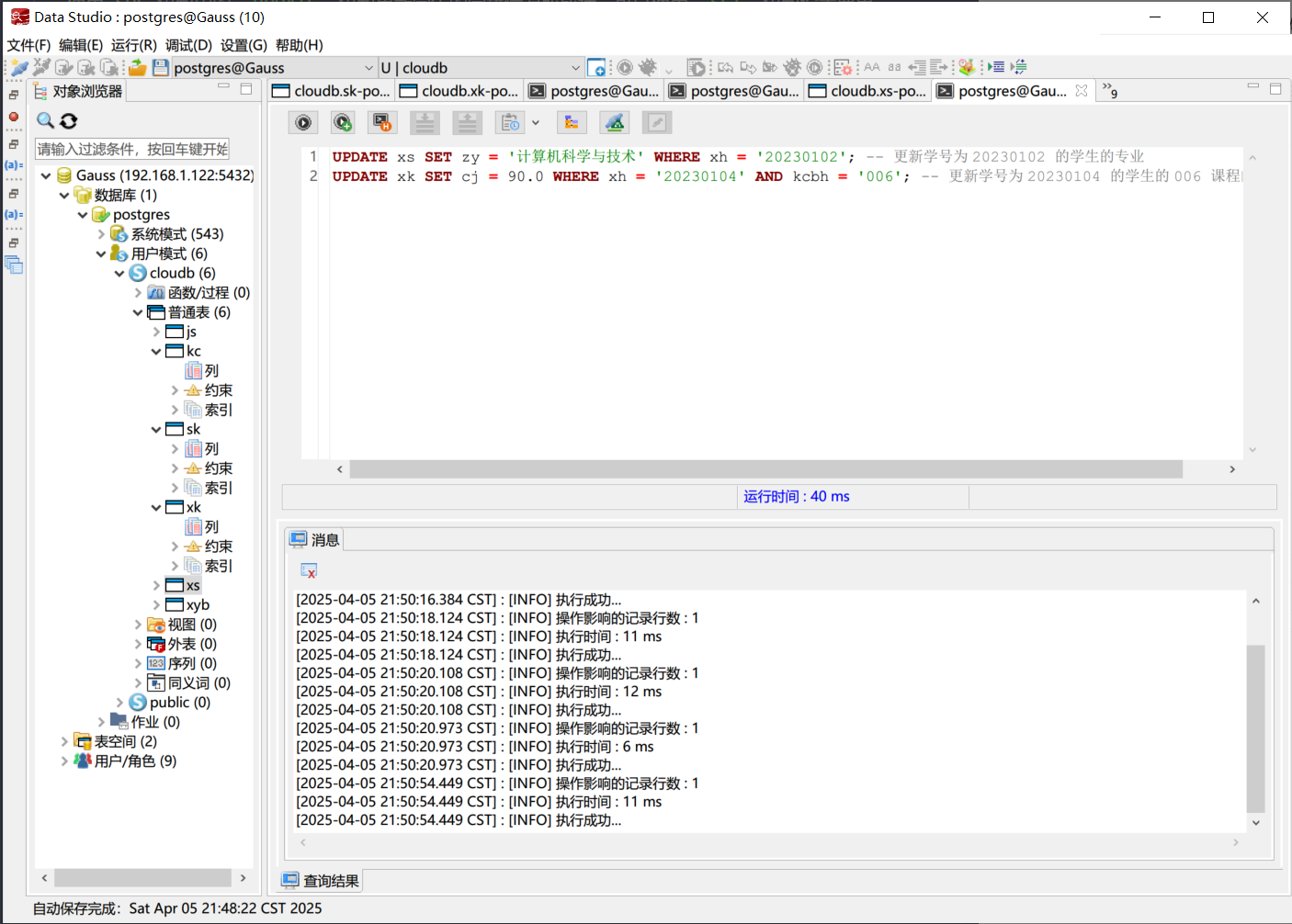
删除部分同学的学籍信息
使用 SQL 语句中的 DELETE 语句删除学生的学籍信息。可以使用 WHERE 子句指定要删除的记录。
例如, 删除学号为 20230103 的学生的学籍信息, 需要分两步操作,以避免违反数据库的外键约束(例如 xk 表中的外键引用 xs.xh)。
| |
实验结论
通过本次数据库查询实验,我在学籍与成绩管理系统数据库中成功完成了多种数据操作,获得了以下结论:
- 数据库连接与管理工具
- PuTTY和Data Studio作为数据库连接和管理工具,提供了便捷的方式访问OpenGauss数据库,其中Data Studio的图形化界面使数据操作更加直观高效。
- Data Studio支持SQL脚本执行、可视化数据浏览与编辑、图形化查询设计等功能,大大提高了数据库操作的效率。
- 外键约束的作用
- 在尝试插入含有不存在外键值的数据时,系统会自动拒绝并报错,这证明了外键约束在保证数据完整性方面的重要作用。
- 外键约束接受NULL值,这为数据的灵活录入提供了便利,比如学生可以不立即确定所属学院。
- 在删除操作中,必须先删除子表中的相关记录,再删除主表记录,否则会违反引用完整性。
- SQL查询能力
- 使用
SELECT语句可以方便地实现简单查询,而结合JOIN、GROUP BY等子句可以实现复杂的关联查询。 LEFT JOIN的使用确保了即使无关联数据的记录也能在结果中显示,提高了查询结果的完整性。- 聚合函数(如
SUM、AVG、COUNT)结合GROUP BY子句,可以有效地进行统计分析,如计算学生的总学分、平均分、选课数量等。
- 数据修改操作
- 通过
UPDATE语句可以方便地更新数据库中的记录,如修改学生的专业、成绩等信息。 DELETE语句用于删除记录,但在有外键约束的情况下必须注意操作顺序,先删除子表记录再删除主表记录。- 在进行数据修改操作时,
WHERE子句的使用至关重要,它确保只有符合条件的记录被修改。
- 索引的应用
- 针对常用查询字段创建索引可以显著提高查询效率,如学号、课程编号、教师编号等字段。
- 对于关联查询频繁的外键字段,建立索引有助于提高
JOIN操作的效率。 - 对经常用于排序和分组的字段(如成绩、学分)建立索引也能提升这类操作的性能。
实验体会
本次实验让我深入理解了SQL语言在数据库查询和管理中的实际应用,掌握了多种数据库操作技术,获得了以下体会:
数据库设计与数据完整性:合理的表结构设计和外键约束对于保证数据完整性至关重要。外键约束不仅能防止错误数据的插入,也能维护表间的引用关系,确保数据的一致性。
查询语句的灵活运用:SQL查询语言功能强大,通过
JOIN、GROUP BY、ORDER BY等子句的组合使用,可以灵活地实现各种复杂查询需求。掌握这些技巧对于数据分析和信息提取非常重要。数据管理工具的重要性:像Data Studio这样的图形化管理工具大大简化了数据库操作,提高了工作效率。它不仅支持SQL语句执行,还提供了表格可视化、结果导出等功能,对于初学者和专业人员都很有帮助。
实践中的问题解决:在实验过程中遇到的问题,如外键约束导致的插入失败、删除时需要考虑的表间依赖关系等,使我更加深入地理解了数据库系统的工作原理和约束机制。
索引与性能优化:通过创建适当的索引,可以显著提高查询性能。但同时也需要权衡索引带来的写入性能开销,在实际应用中需要根据业务需求合理设计索引策略。
总的来说,本次实验使我对数据库操作有了更为全面和深入的认识,特别是在数据查询和修改方面积累了宝贵的实践经验。这些技能对于今后从事软件开发、数据分析等工作都将发挥重要作用。同时,也认识到了数据库作为信息系统核心组件的重要性,以及SQL语言作为与数据库交互的标准工具的强大功能。