实验任务
- 创建数据分区表
- 体会主键、外键约束
- 练习更新、删除主表数据(针对主键属性且子表中可能有参照外键数据)
- 练习更新、删除主表数据(针对非主键属性)
- 练习先删除子表数据,再删除主表数据
- 使用子查询方式更新、删除数据
- 体会索引
- 权限管理
- 以不同身份用户登录数据库建立表
- 以不同身份用户查询自己与其他用户建立的表
- 定义授权方案并进行验证
实验过程
创建数据分区表
分区表是指将一个大表按照某种规则分解成多个更小的、更容易管理的部分。每个部分称为一个分区,从逻辑上看是一个完整的表,但物理上这些数据分布在不同的表空间中。
分区表的优势包括:
- 提升查询性能:通过分区消除,可以只扫描必要的分区,减少数据扫描量
- 更易维护:可以独立管理各个分区,便于数据的备份和恢复
- 改善可用性:分区故障只影响单个分区,不影响整个表的使用
- 均衡I/O:数据分散存储,可以降低I/O争用
常见分区方式有:
- 范围分区:根据分区键的值范围将数据分配到不同分区
- 列表分区:根据分区键的离散值列表进行分区
- 哈希分区:使用哈希函数将数据均匀分布到各个分区
- 复合分区:组合使用多种分区方式
本次实验中, 我们将按和之前一样的格式创建 xs 表, 但按学生的入学年份进行范围分区。例如学生的学号为 20230101,则其入学年份为 2023。
| 字段名 | 字段含义 | 字段类型 | 字段长度 | NULL | 备注 |
|---|
| xm | 姓名 | 字符 | 8 | | |
| xh | 学号 | 字符 | 10 | | PK |
| ydh | 所属学院代号 | 字符 | 2 | ✓ | FK |
| bj | 班级 | 字符 | 8 | ✓ | |
| chrq | 出生日期 | 日期 | | ✓ | |
| xb | 性别 | 字符 | 2 | ✓ | |
为防止与之前的学生管理系统冲突, 我们将创建一个新的 Schema partition_test,并在其中创建分区表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| CREATE SCHEMA IF NOT EXISTS partition_test;
CREATE TABLE IF NOT EXISTS partition_test.xs (
xm VARCHAR(8) NOT NULL,
xh VARCHAR(10) NOT NULL PRIMARY KEY,
ydh CHAR(2) NOT NULL,
bj VARCHAR(8) NULL,
chrq DATE NULL,
xb CHAR(2) NULL
) PARTITION BY RANGE (xh) (
PARTITION p_old VALUES LESS THAN ('20200000'),
PARTITION p_2020 VALUES LESS THAN ('20210000'),
PARTITION p_2021 VALUES LESS THAN ('20220000'),
PARTITION p_2022 VALUES LESS THAN ('20230000'),
PARTITION p_2023 VALUES LESS THAN ('20240000'),
PARTITION p_2024 VALUES LESS THAN ('20250000')
);
|
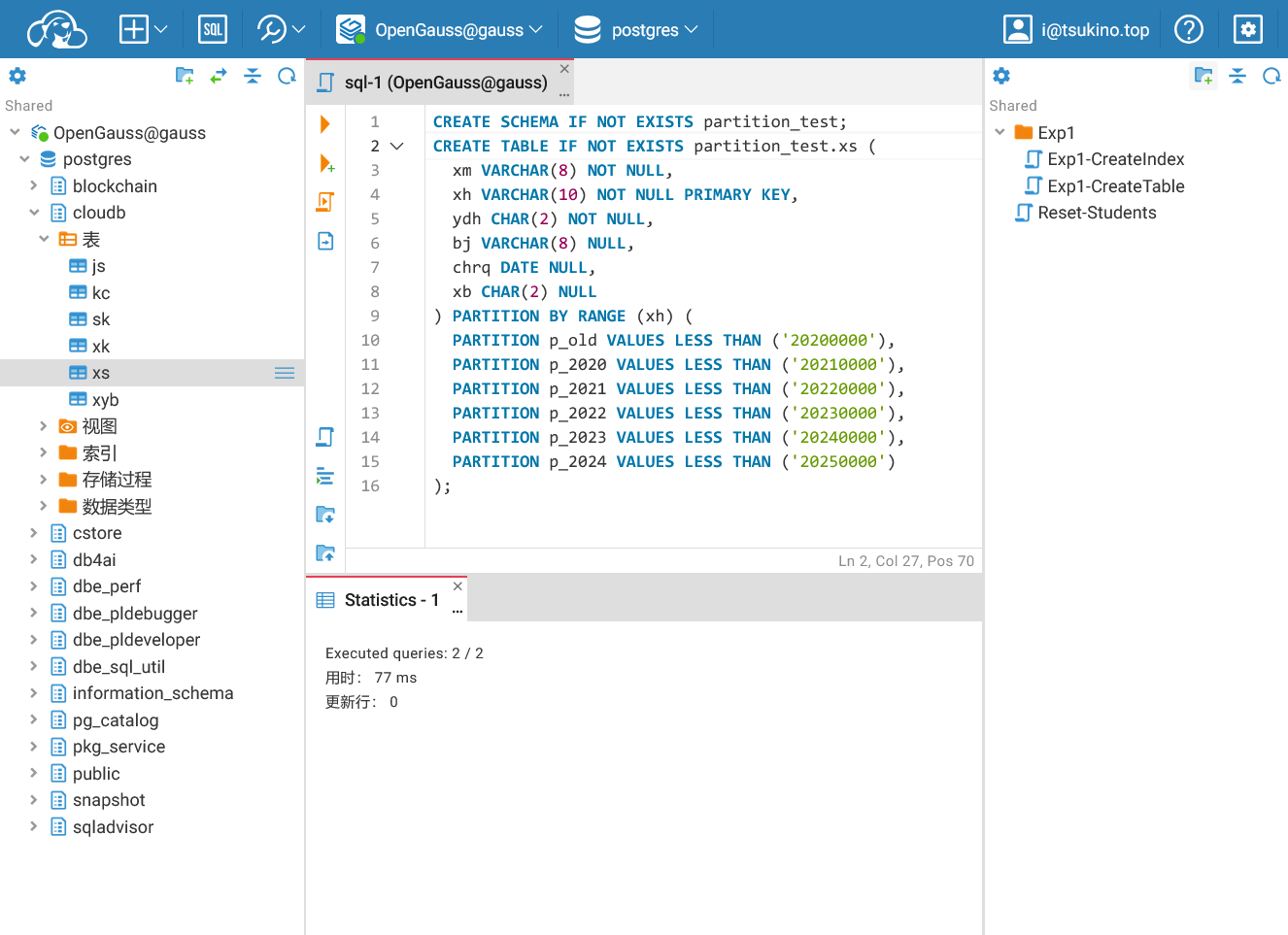 在Cloudbeaver中连接数据库并创建Schema与分区表
在Cloudbeaver中连接数据库并创建Schema与分区表创建成功之后, 向 xs 表中插入数据。
1
2
3
4
5
| INSERT INTO partition_test.xs (xm, xh, ydh, bj, chrq, xb) VALUES
('张三', '20230101', '01', '软件工程', '2003-01-01', '男'),
('李四', '20220102', '02', '计算机科学', '2002-02-02', '女'),
('王五', '20210103', '03', '网络工程', '2001-03-03', '男'),
('赵六', '20200104', '04', '信息管理', '2000-04-04', '女');
|
在 Data Studio 左侧的树形结构中, 可以看到 partition_test Schema 下的 xs 表已经有了六个分区。查看分区中的数据, 可以看到数据的储存符合我们的设计预期, 入学年份为 2023 年的学生 张三 被储存在了 p_2023 分区中.
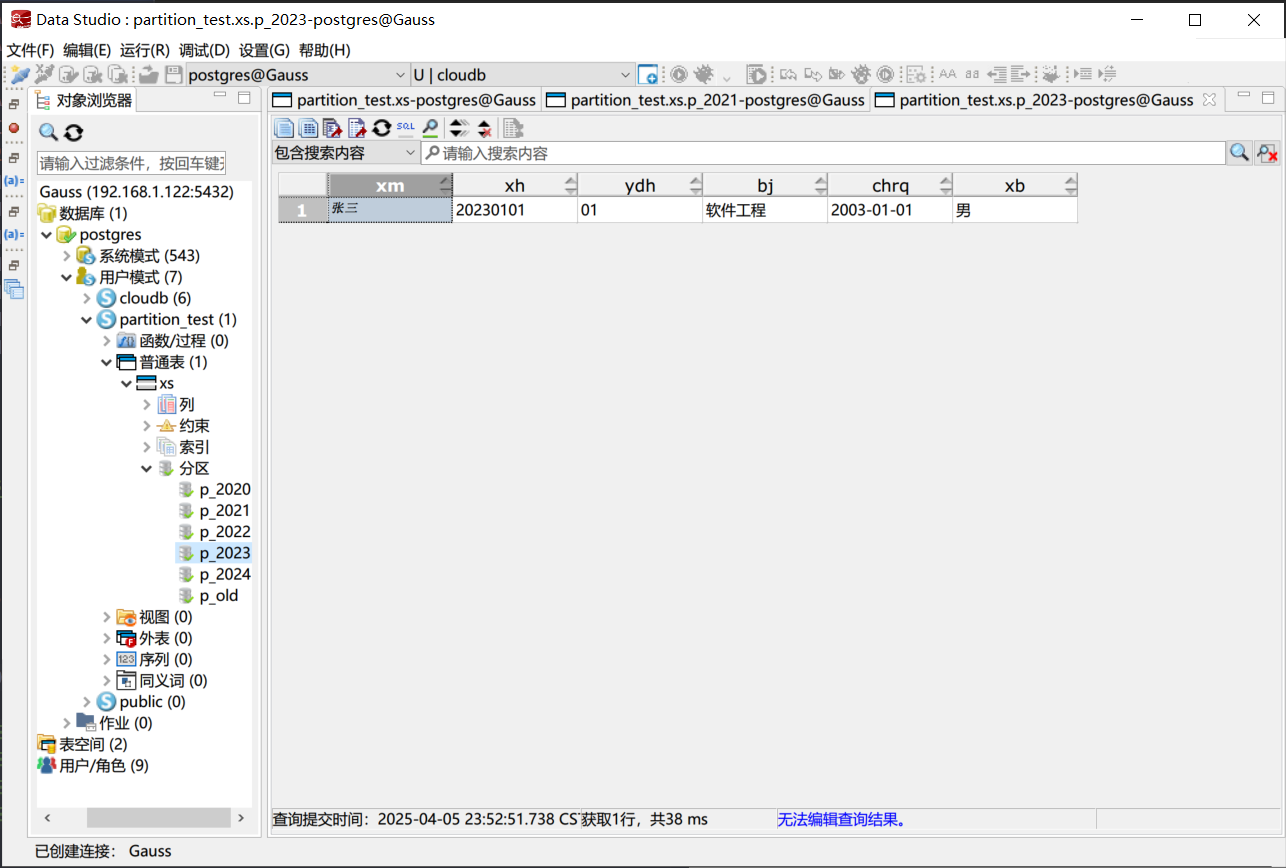 在Data Studio中查看分区表
在Data Studio中查看分区表体会主键、外键约束
在每次练习之前, 都先将数据库中的所有数据恢复到实验二中插入数据之后的状态, 以免影响实验结果.
练习更新、删除主表数据(针对主键属性且子表中可能有参照外键数据)
更新数据
将学生表中学号为 20230108 的学生的学号改为 20230111,并更新所有表中与这个学生相关的记录.
如果我们直接使用下面的 SQL 语句进行更新的话, 会导致外键约束错误, 因为在成绩表中有一条记录通过外键约束引用了学生表中的学号 20230108.
1
| UPDATE xs SET xh='20230111' WHERE xh='20230108';
|
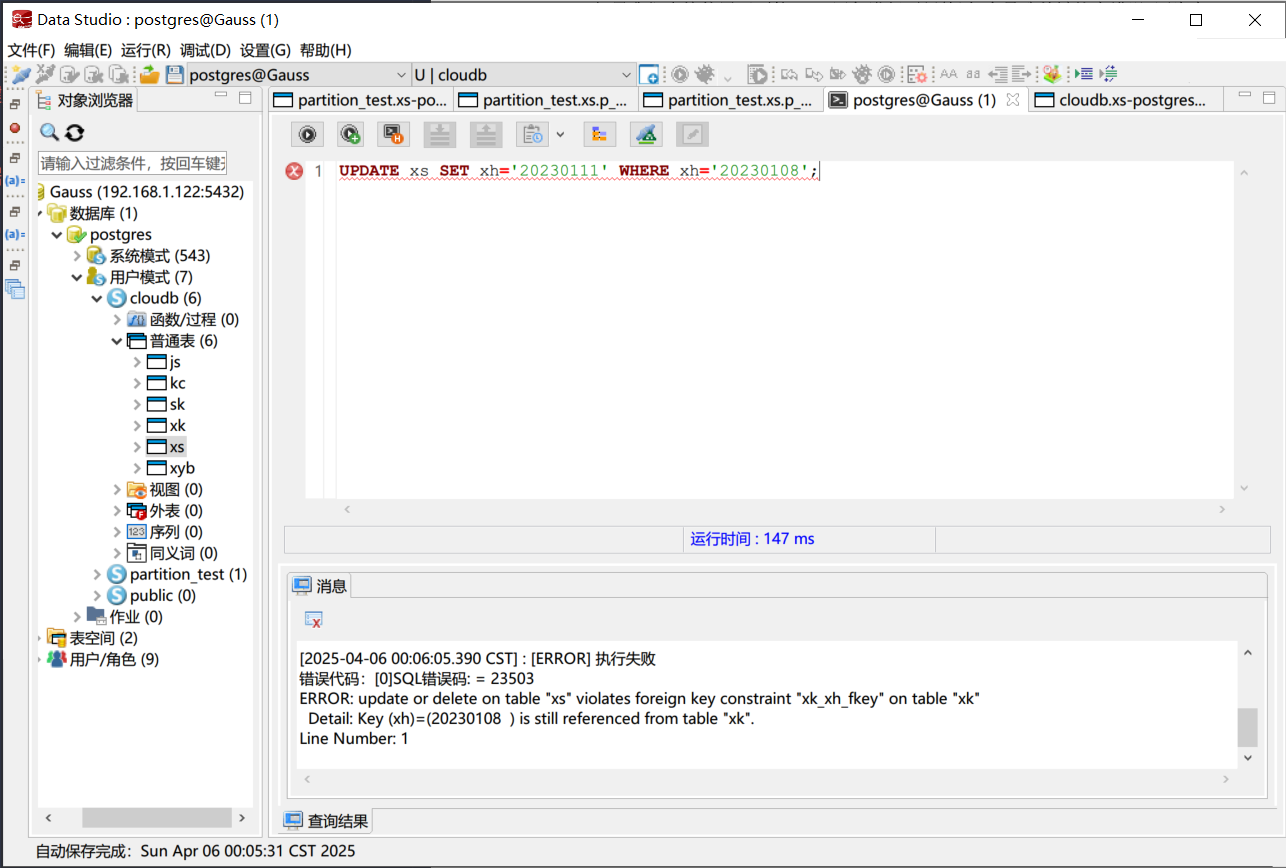 更新主键属性时的外键约束错误
更新主键属性时的外键约束错误在这种情况下, 如果要修改主表的主键属性, 我们需要先删除子表中引用了这个主键的记录, 然后再进行更新操作. 在更新之后, 我们需要重新插入之前删除的记录. 这种操作显然是比较繁琐, 且容易出错的, 因为我们需要手动删除和插入记录; 一旦我们在删除记录后忘记将记录添加回数据表, 就会导致数据的丢失.
为了避免这种情况, 我们可以使用 ON UPDATE CASCADE 选项来定义外键约束, 这样在更新主表的主键属性时, 子表中引用了这个主键的记录会自动更新.
用下面的 SQL 语句, 为数据表创建所需的外键约束.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| ALTER TABLE xs DROP CONSTRAINT IF EXISTS xs_ydh_fkey;
ALTER TABLE xs ADD CONSTRAINT xs_ydh_fkey
FOREIGN KEY (ydh) REFERENCES xyb(ydh)
ON UPDATE CASCADE ON DELETE CASCADE;
ALTER TABLE js DROP CONSTRAINT IF EXISTS js_ydh_fkey;
ALTER TABLE js ADD CONSTRAINT js_ydh_fkey
FOREIGN KEY (ydh) REFERENCES xyb(ydh)
ON UPDATE CASCADE ON DELETE CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS xk_xh_fkey;
ALTER TABLE xk ADD CONSTRAINT xk_xh_fkey
FOREIGN KEY (xh) REFERENCES xs(xh)
ON UPDATE CASCADE ON DELETE CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS xk_kcbh_fkey_1;
ALTER TABLE xk ADD CONSTRAINT xk_kcbh_fkey_1
FOREIGN KEY (kcbh,jsbh) REFERENCES sk(kcbh,bh)
ON UPDATE CASCADE ON DELETE CASCADE;
|
成功创建外键约束后, 我们可以直接使用下面的 SQL 语句进行更新操作.
1
| UPDATE xs SET xh='20230111' WHERE xh='20230108';
|
此时, 子表中引用了这个主键的记录会自动更新, 不需要手动删除和插入记录.
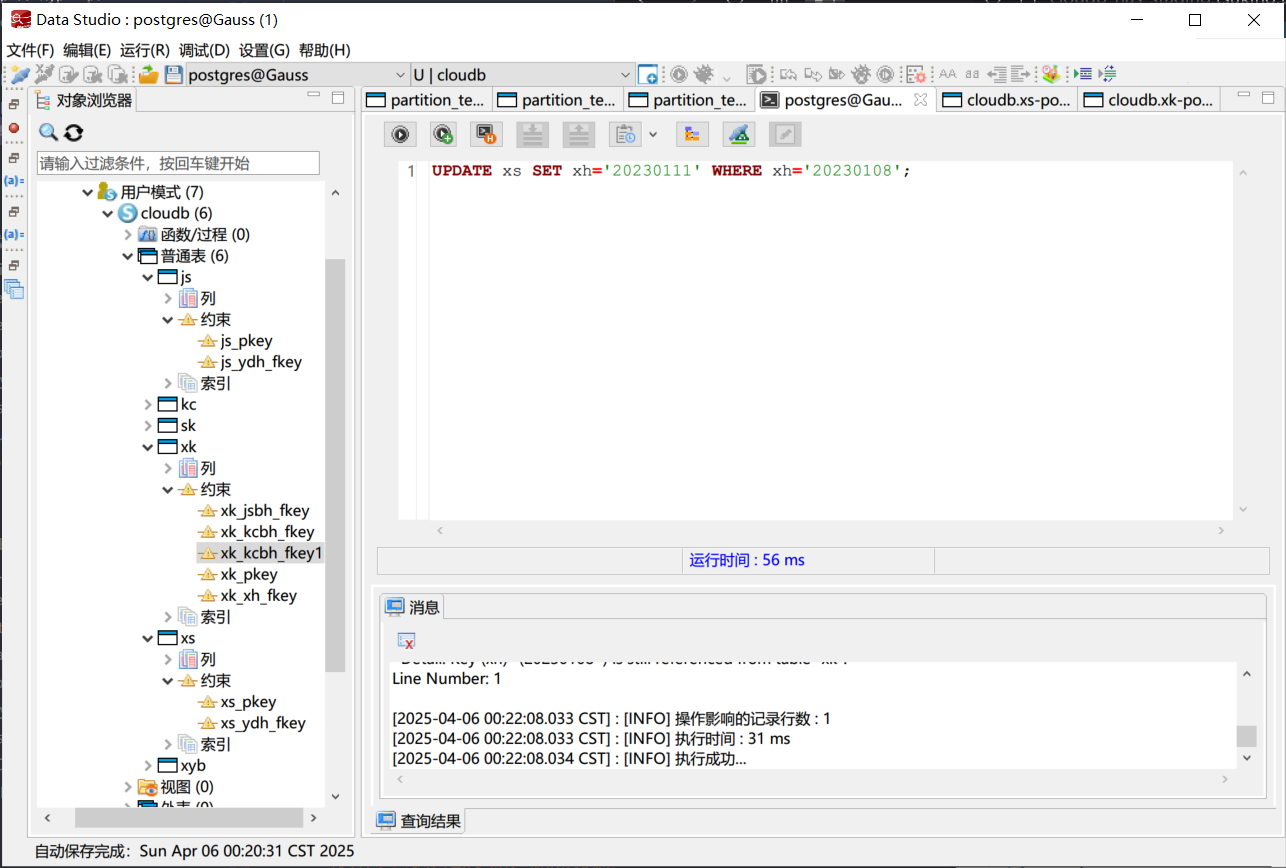 更新主键属性时的外键约束成功
更新主键属性时的外键约束成功删除数据
现在将学生表中学号为 20230111 的学生删除. 由于我们已经为外键约束定义了 ON DELETE CASCADE 选项, 所以在删除主表的主键属性时, 子表中引用了这个主键的记录会自动删除.
所以我们可以直接使用下面的 SQL 语句进行删除操作.
1
| DELETE FROM xs WHERE xh='20230111';
|
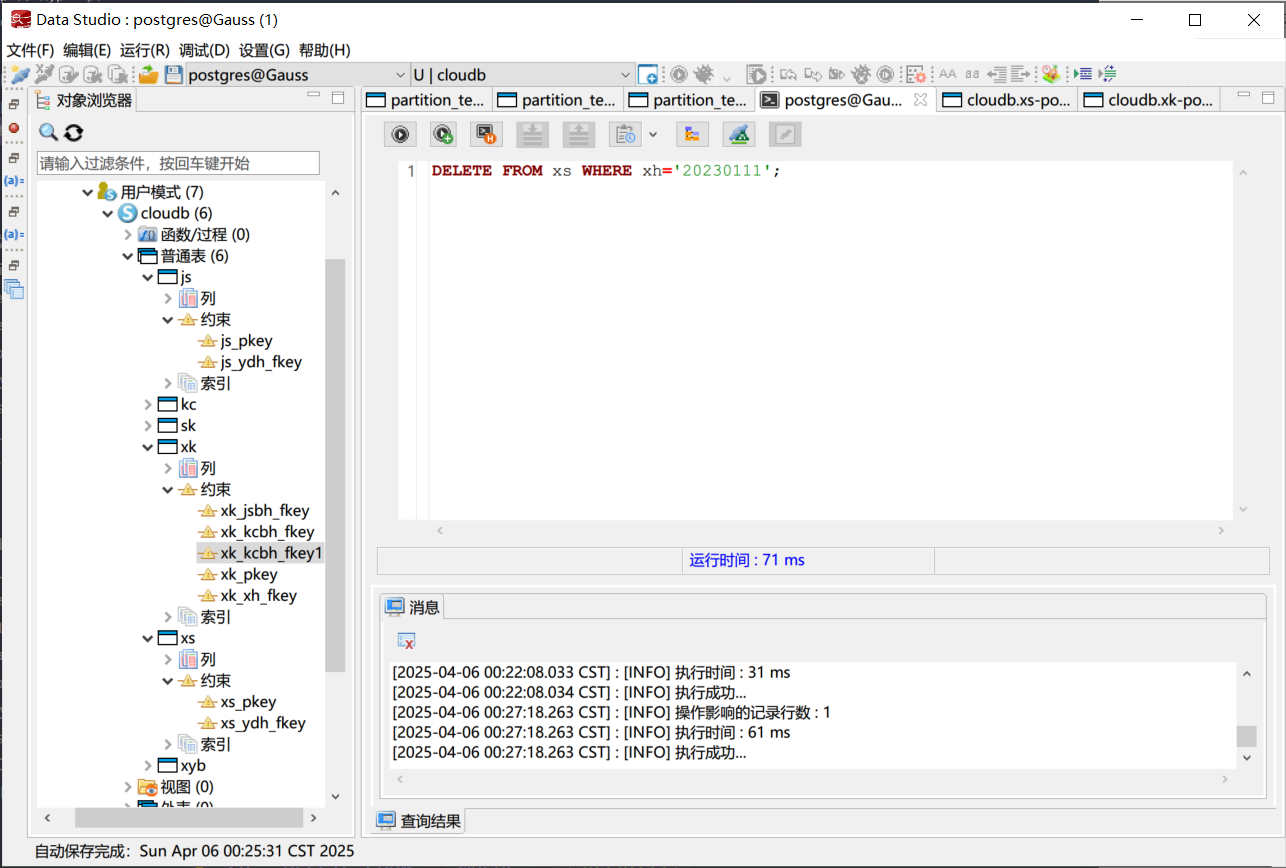 删除带有外键约束的主键属性成功
删除带有外键约束的主键属性成功我们可以通过下面的 SQL 语句确定学号为 20230111 的学生以及其选课记录已经被删除.
1
2
| SELECT * FROM xs WHERE xh='20230111';
SELECT * FROM xk WHERE xh='20230111';
|
可以看见, 查询的结果为空, 说明学号为 20230111 的学生已经被删除, 其选课记录也因为外键约束而被删除.
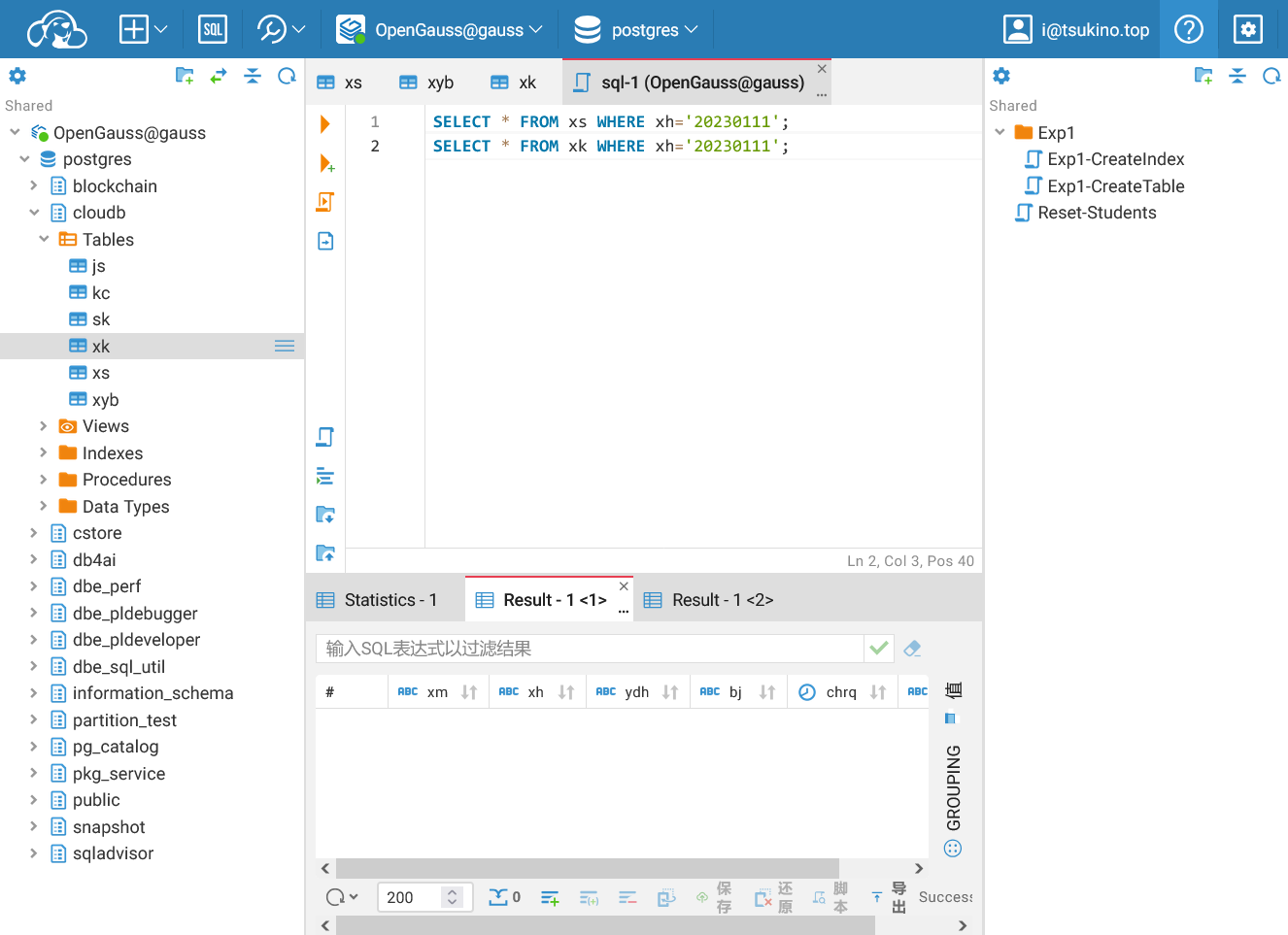 外键层联删除成功
外键层联删除成功练习更新、删除主表数据(针对非主键属性)
更新数据
重置数据表后, 将学生表中学号为 20230108 的学生的姓名改为 长崎素世.
1
2
| UPDATE xs SET xm='长崎素世' WHERE xh='20230108';
SELECT * FROM xs WHERE xh='20230108';
|
可以看见, 在更新数据之后, 查询的结果显示, 学号为 20230108 的学生的姓名已经被修改为 长崎素世.
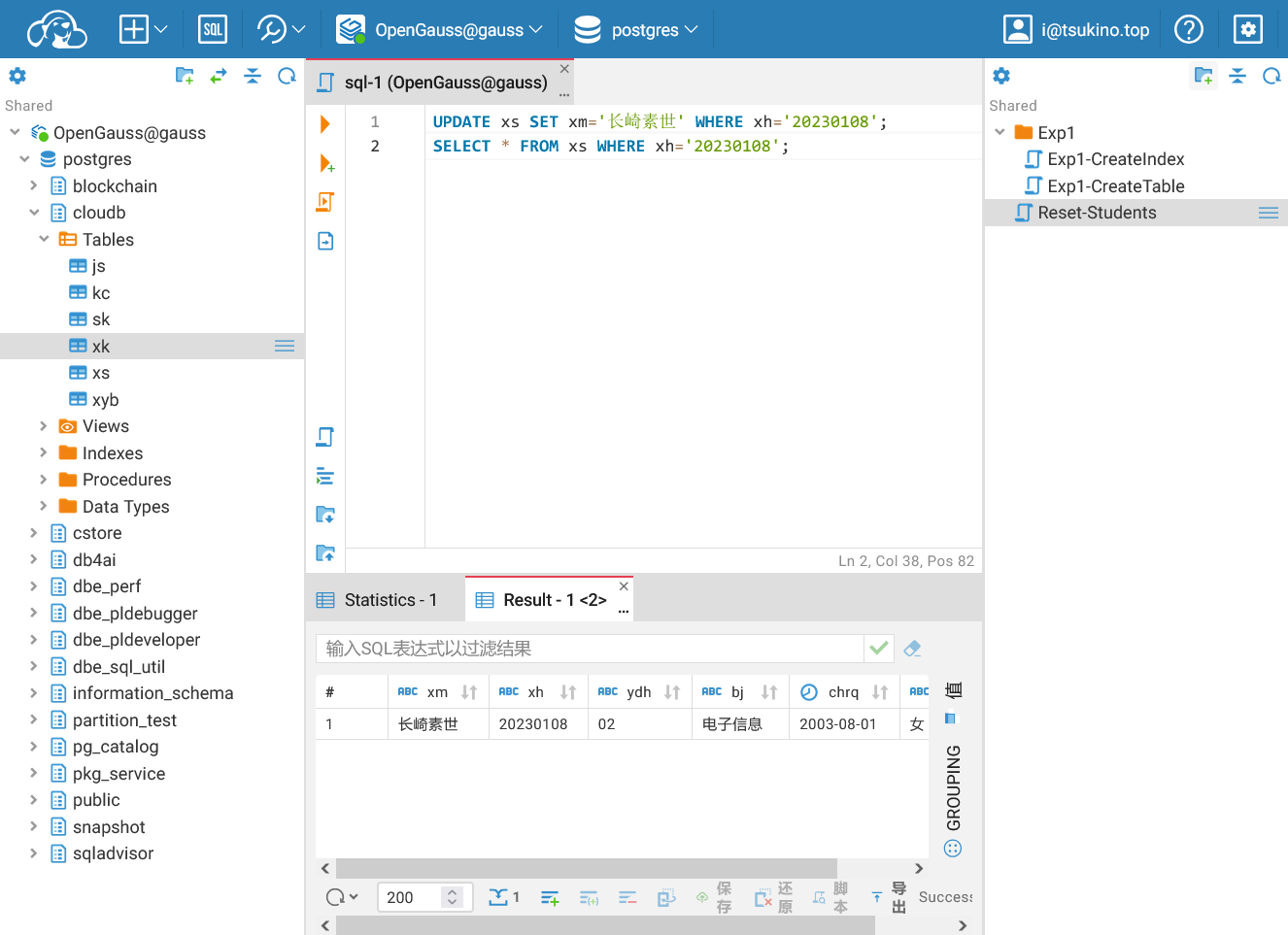 更新非主键属性成功
更新非主键属性成功删除数据
要删除学号为 20230108 的学生, 由于我们没有为外键约束定义 ON DELETE CASCADE 选项, 所以仍需要先按上面的方法创建外键约束, 这样在删除主表的记录时, 子表中的相关记录会自动删除.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
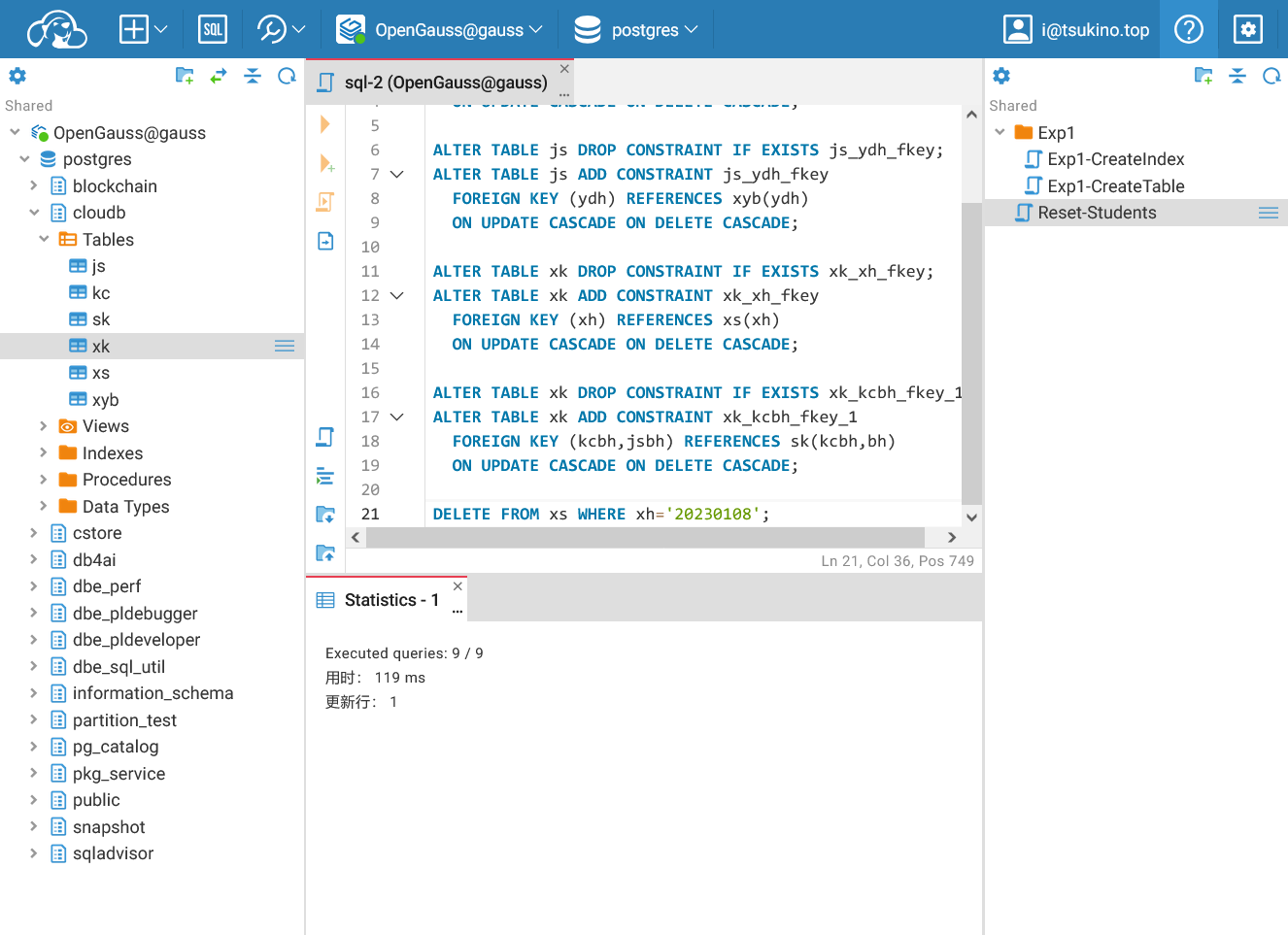
| ALTER TABLE xs DROP CONSTRAINT IF EXISTS xs_ydh_fkey;
ALTER TABLE xs ADD CONSTRAINT xs_ydh_fkey
FOREIGN KEY (ydh) REFERENCES xyb(ydh)
ON UPDATE CASCADE ON DELETE CASCADE;
ALTER TABLE js DROP CONSTRAINT IF EXISTS js_ydh_fkey;
ALTER TABLE js ADD CONSTRAINT js_ydh_fkey
FOREIGN KEY (ydh) REFERENCES xyb(ydh)
ON UPDATE CASCADE ON DELETE CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS xk_xh_fkey;
ALTER TABLE xk ADD CONSTRAINT xk_xh_fkey
FOREIGN KEY (xh) REFERENCES xs(xh)
ON UPDATE CASCADE ON DELETE CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS xk_kcbh_fkey_1;
ALTER TABLE xk ADD CONSTRAINT xk_kcbh_fkey_1
FOREIGN KEY (kcbh,jsbh) REFERENCES sk(kcbh,bh)
ON UPDATE CASCADE ON DELETE CASCADE;
|
创建外键约束后, 我们可以直接使用下面的 SQL 语句进行删除操作.
1
| DELETE FROM xs WHERE xh='20230108';
|
 删除非主键属性成功
删除非主键属性成功练习先删除子表数据,再删除主表数据
重置数据库之后, 删除土木工程学院 (代号为05) 的相关信息,并把属于土木工程学院的同学,老师,授课信息以及同学的选课信息删除。
这个操作无法直接使用 ON DELETE CASCADE 选项来实现, 我们必须按照 依赖关系的逆序 删除数据,即从 最底层的引用表 开始删除,逐步向上删除高层表。
1
2
3
4
5
6
| DELETE xk WHERE xk.jsbh IN (SELECT jsbh FROM js WHERE ydh = '05');
DELETE xk WHERE xk.xh IN (SELECT xh FROM xs WHERE ydh = '05');
DELETE sk WHERE sk.bh IN (SELECT jsbh FROM js WHERE ydh = '05');
DELETE js WHERE ydh = '05';
DELETE xs WHERE ydh = '05';
DELETE xyb WHERE ydh = '05';
|
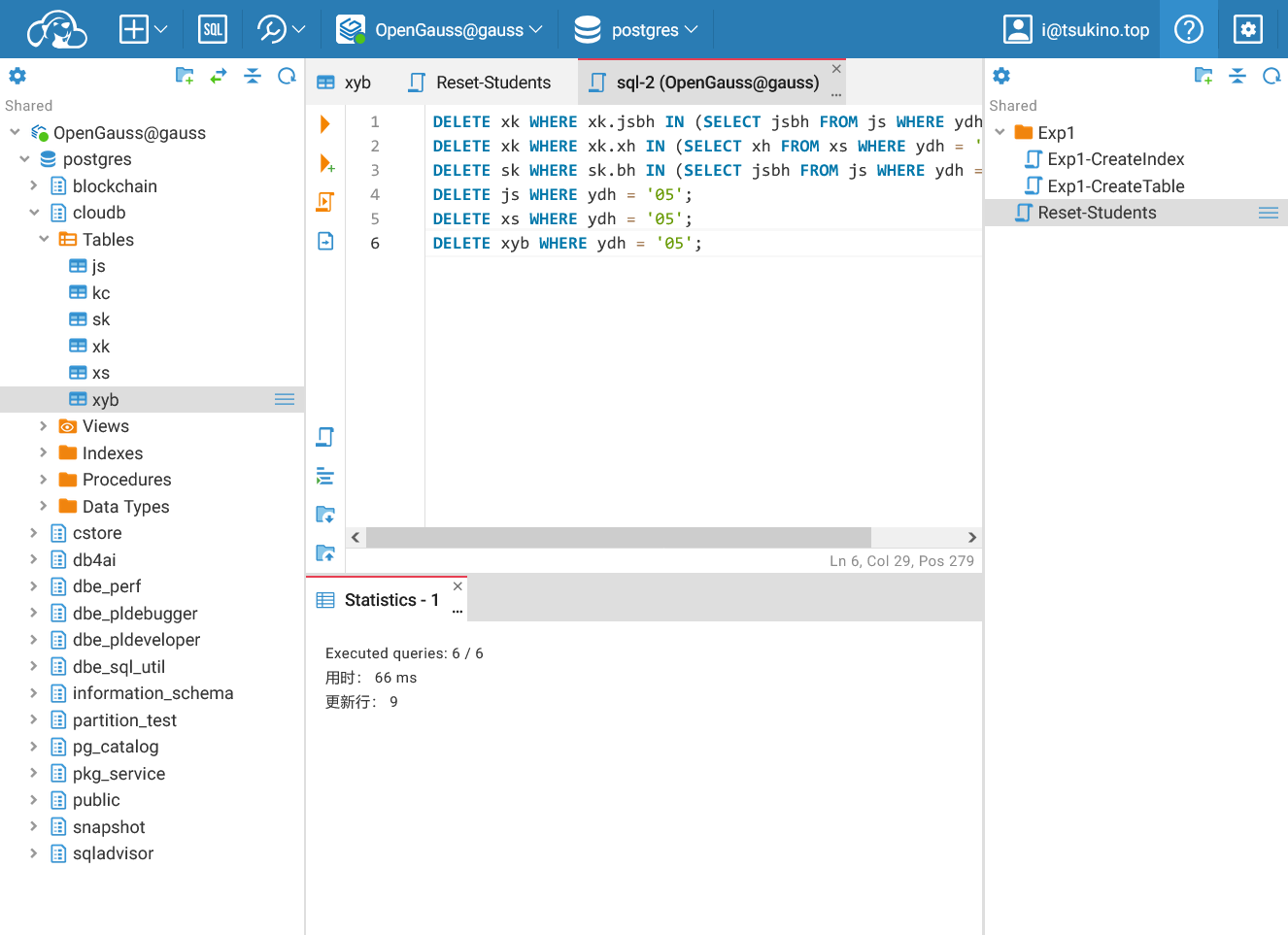 成功按顺序删除子表格后删除主表格
成功按顺序删除子表格后删除主表格使用子查询方式更新、删除数据
更新数据
重置数据表后, 找出没有任何一门成绩小于80的同学,将他们的班级信息更新为“全优良”。
我们可以使用子查询的方式完成这个操作, SQL语句如下:
1
2
3
4
5
6
| UPDATE xs SET bj='全优良' WHERE xh IN (
SELECT xh FROM xs WHERE xh NOT IN (
SELECT xh FROM xk WHERE cj < 80
)
);
SELECT * FROM xs WHERE bj='全优良';
|
可以看见, 在更新数据之后查询的结果显示, 没有任何一门成绩小于80的同学的班级都为 全优良.
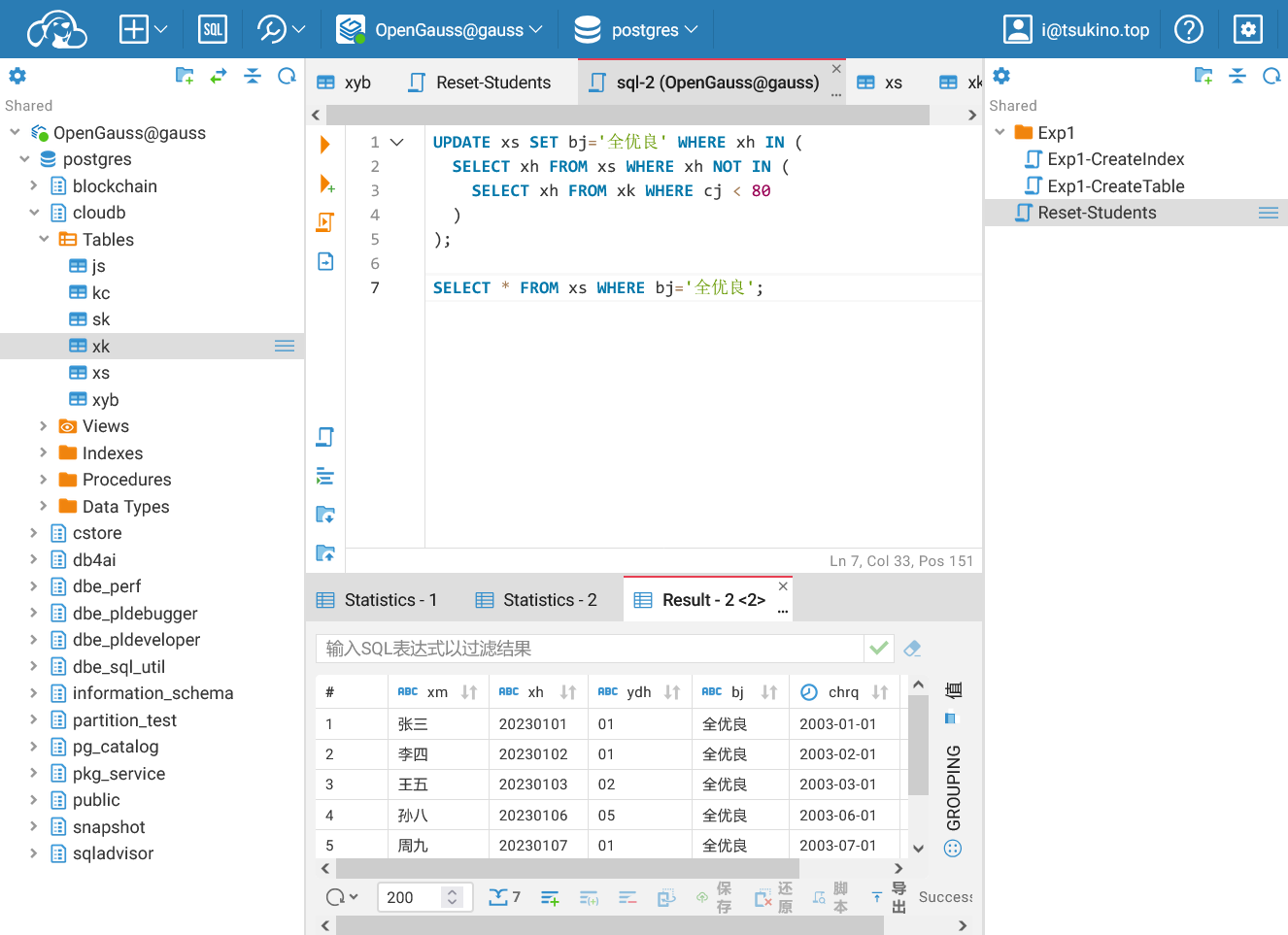 使用子查询更新数据成功
使用子查询更新数据成功删除数据
找出任意一门选课成绩小于75的同学,将他们的信息删除。
同样这需要为外键约束定义 ON DELETE CASCADE 选项, 这样在删除主表的记录时, 子表中的相关记录会自动删除.
添加外键约束后, 我们可以直接使用下面的 SQL 语句进行删除操作.
1
2
3
4
5
6
7
8
9
10
11
| DELETE FROM xs WHERE xh IN (
SELECT xh FROM xs WHERE xh IN (
SELECT xh FROM xk WHERE cj < 75
)
);
-- 删除后检查
SELECT * FROM xs WHERE xh IN (
SELECT xh FROM xs WHERE xh IN (
SELECT xh FROM xk WHERE cj < 75
)
);
|
可以看见, 在删除数据之后查询的结果显示, 任意一门选课成绩小于75的同学的信息已经被删除.
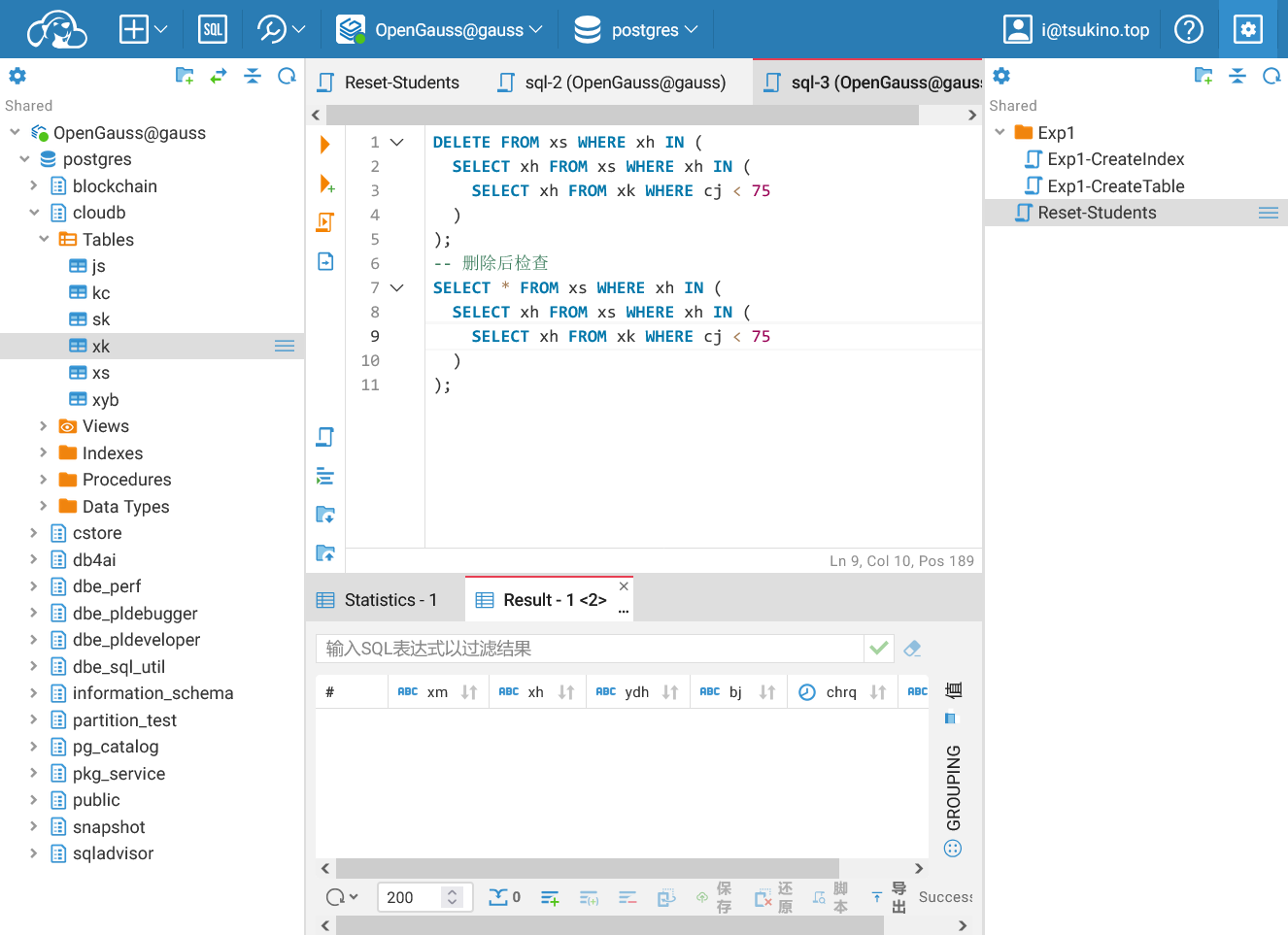 使用子查询删除数据成功
使用子查询删除数据成功体会索引
查询计划 EXPLAIN
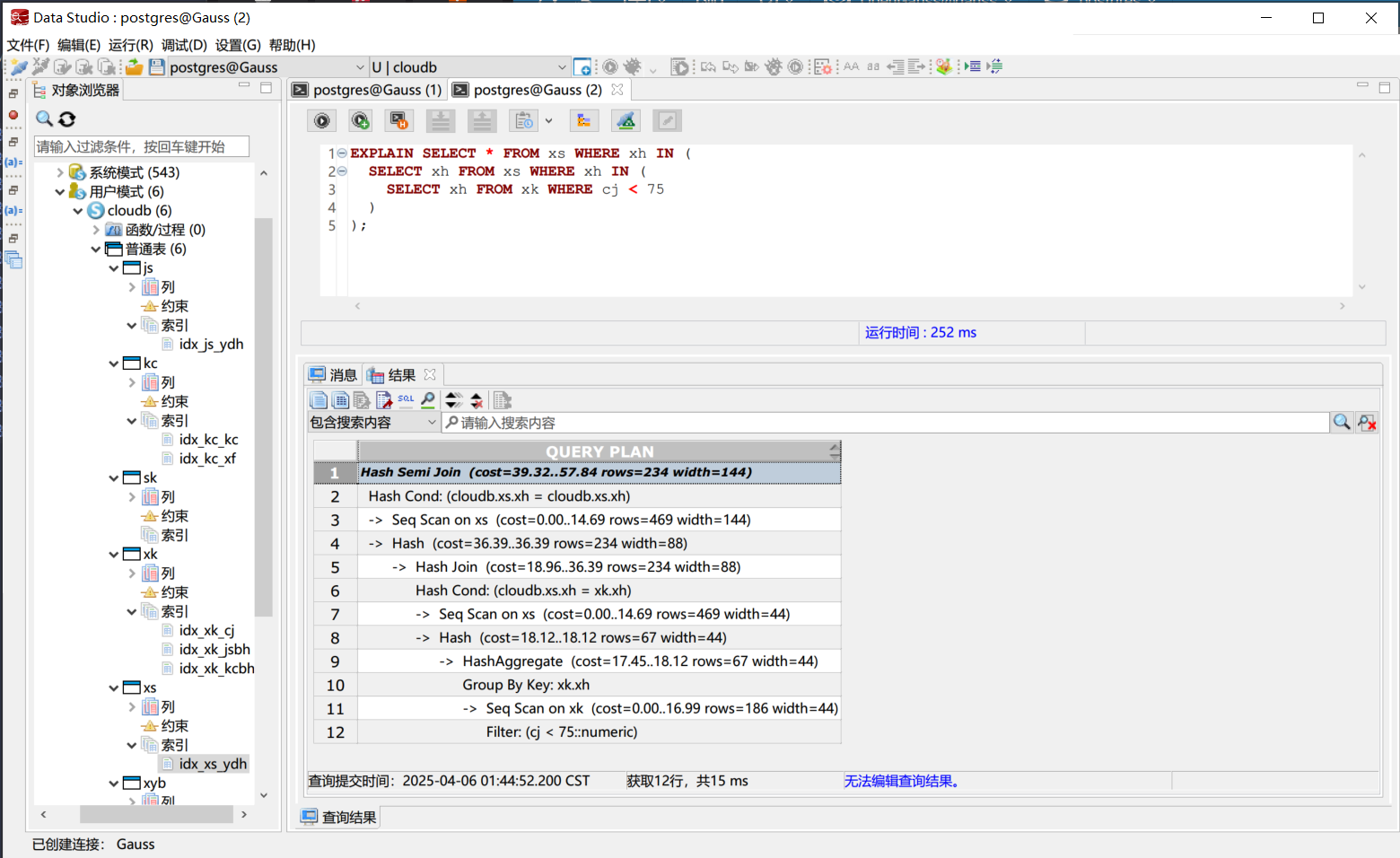
重置数据库之后, 利用查询计划 (EXPLAIN) 对查询语句进行分析。
1
2
3
4
5
| EXPLAIN SELECT * FROM xs WHERE xh IN (
SELECT xh FROM xs WHERE xh IN (
SELECT xh FROM xk WHERE cj < 75
)
);
|
在图中,我们可以看到每一步运行的时间,从而可以判断哪一步是最需要优化的步骤。
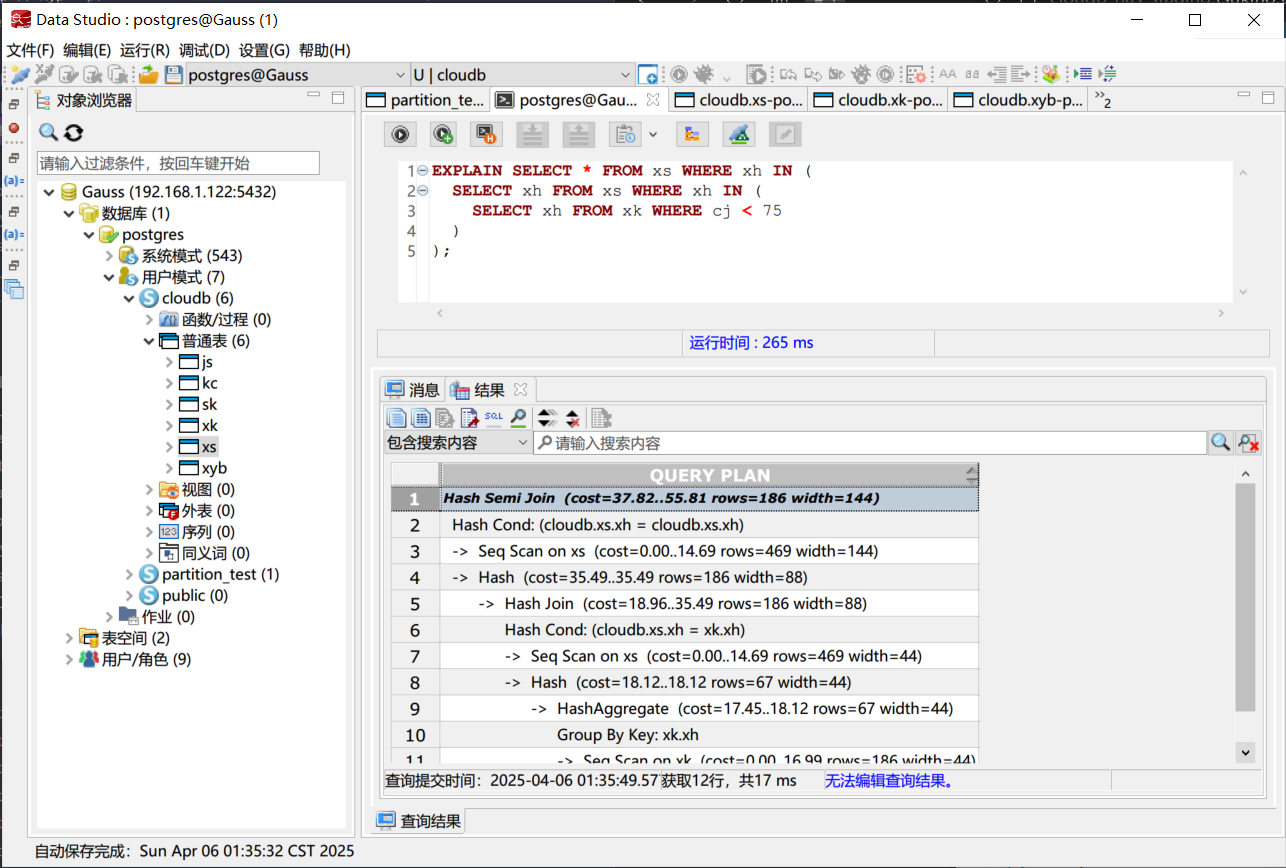 查询计划分析
查询计划分析接下来,我们观察去掉所有约束和主键索引后查询效率发生的变化.
1
2
3
4
5
6
7
8
9
10
11
12
13
| ALTER TABLE js DROP CONSTRAINT IF EXISTS js_pkey CASCADE;
ALTER TABLE js DROP CONSTRAINT IF EXISTS idx_js_ydh CASCADE;
ALTER TABLE kc DROP CONSTRAINT IF EXISTS kc_pkey CASCADE;
ALTER TABLE kc DROP CONSTRAINT IF EXISTS idx_kc_kc CASCADE;
ALTER TABLE kc DROP CONSTRAINT IF EXISTS idx_kc_xf CASCADE;
ALTER TABLE sk DROP CONSTRAINT IF EXISTS sk_pkey CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS xk_pkey CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS idx_xk_cj CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS idx_xk_jsbh CASCADE;
ALTER TABLE xk DROP CONSTRAINT IF EXISTS idx_xk_kcbh CASCADE;
ALTER TABLE xs DROP CONSTRAINT IF EXISTS xs_pkey CASCADE;
ALTER TABLE xs DROP CONSTRAINT IF EXISTS idx_xs_ydh CASCADE;
ALTER TABLE xyb DROP CONSTRAINT IF EXISTS xyb_pkey CASCADE;
|
 查询计划分析 (没有索引)
查询计划分析 (没有索引)可知建立索引与不建立索引,查询效率确实会发生一定差异。索引提高数据查找的效率,当数据量非常大时将会变得非常显著。如果建立适当的索引,数据库查询效率将会大幅度提高。
我们建立两张测试表, 一张有索引, 而一张无索引, 向两张表中插入大量数据, 用于测试大量数据下的性能差异.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| DROP TABLE IF EXISTS test_table_with_idx;
DROP TABLE IF EXISTS test_table_without_idx;
CREATE TABLE test_table_with_idx(
id INTEGER PRIMARY KEY,
x DECIMAL(5,4)
);
CREATE TABLE test_table_without_idx(
id INTEGER,
x DECIMAL(5,4)
);
DROP INDEX IF EXISTS t_index;
CREATE INDEX t_index ON test_table_with_idx(x);
DO $$
BEGIN
FOR cnt IN 1..100000 LOOP
INSERT INTO test_table_with_idx(id,x) VALUES (cnt,RANDOM());
INSERT INTO test_table_without_idx(id,x) VALUES (cnt,RANDOM());
END LOOP;
END
$$;
|
然后对两张表分别进行大量查询, 观察查询效率的差异.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| DO $$
BEGIN
FOR cnt IN 1..100000 LOOP
PERFORM * FROM test_table_with_idx WHERE x = 0.5;
END LOOP;
END
$$;
DO $$
BEGIN
FOR cnt IN 1..100000 LOOP
PERFORM * FROM test_table_without_idx WHERE x = 0.5;
END LOOP;
END
$$;
|
实验表明, 有索引的情况下100000次查询用时仅需2秒, 而没有索引的情况下用时超过了30分钟. 可以看出, 有索引的查询效率明显高于没有索引的查询效率. 这说明了索引在数据库查询中的重要性, 在数据量较大的情况下, 索引可以显著提高查询效率.
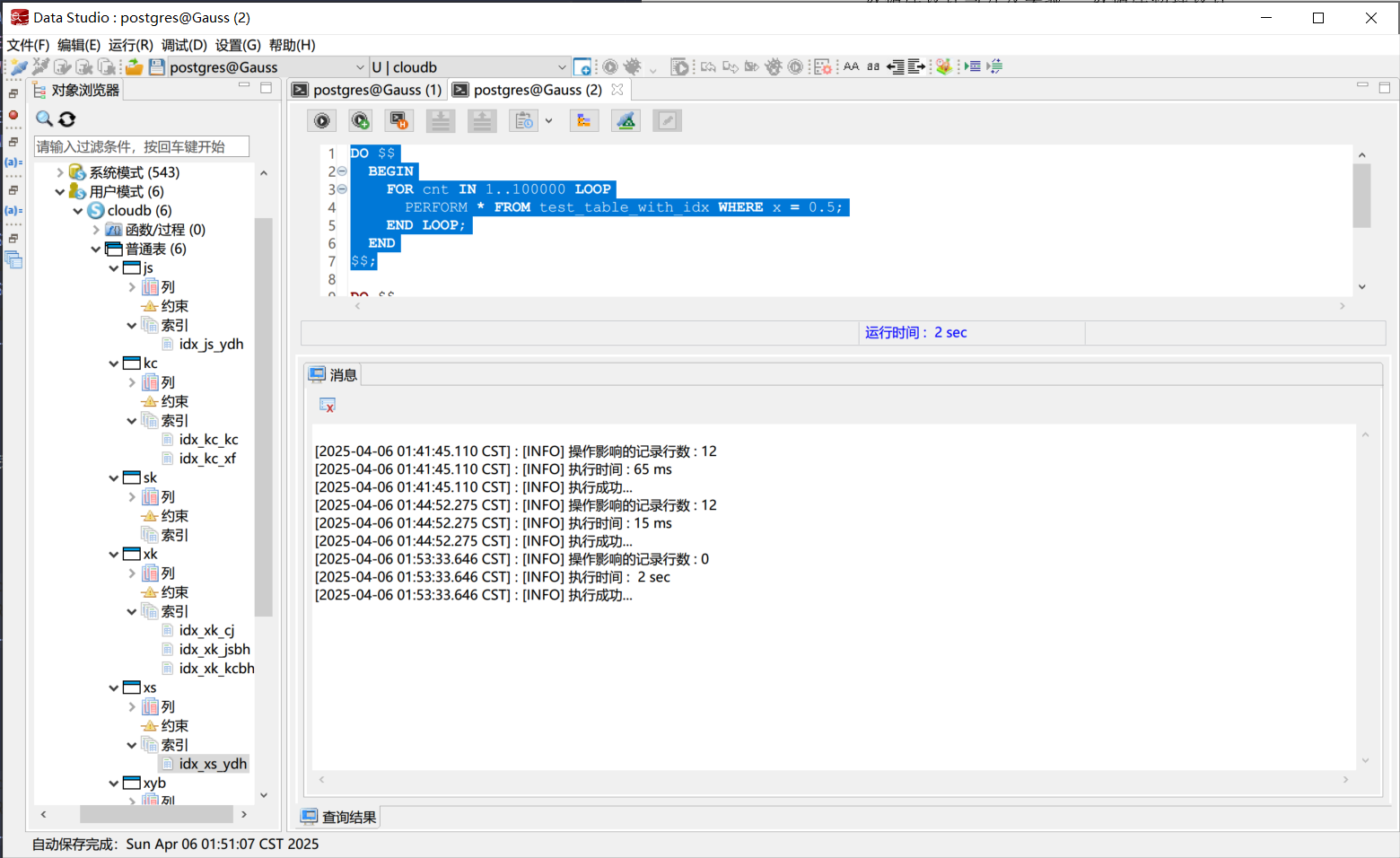 有索引的查询
有索引的查询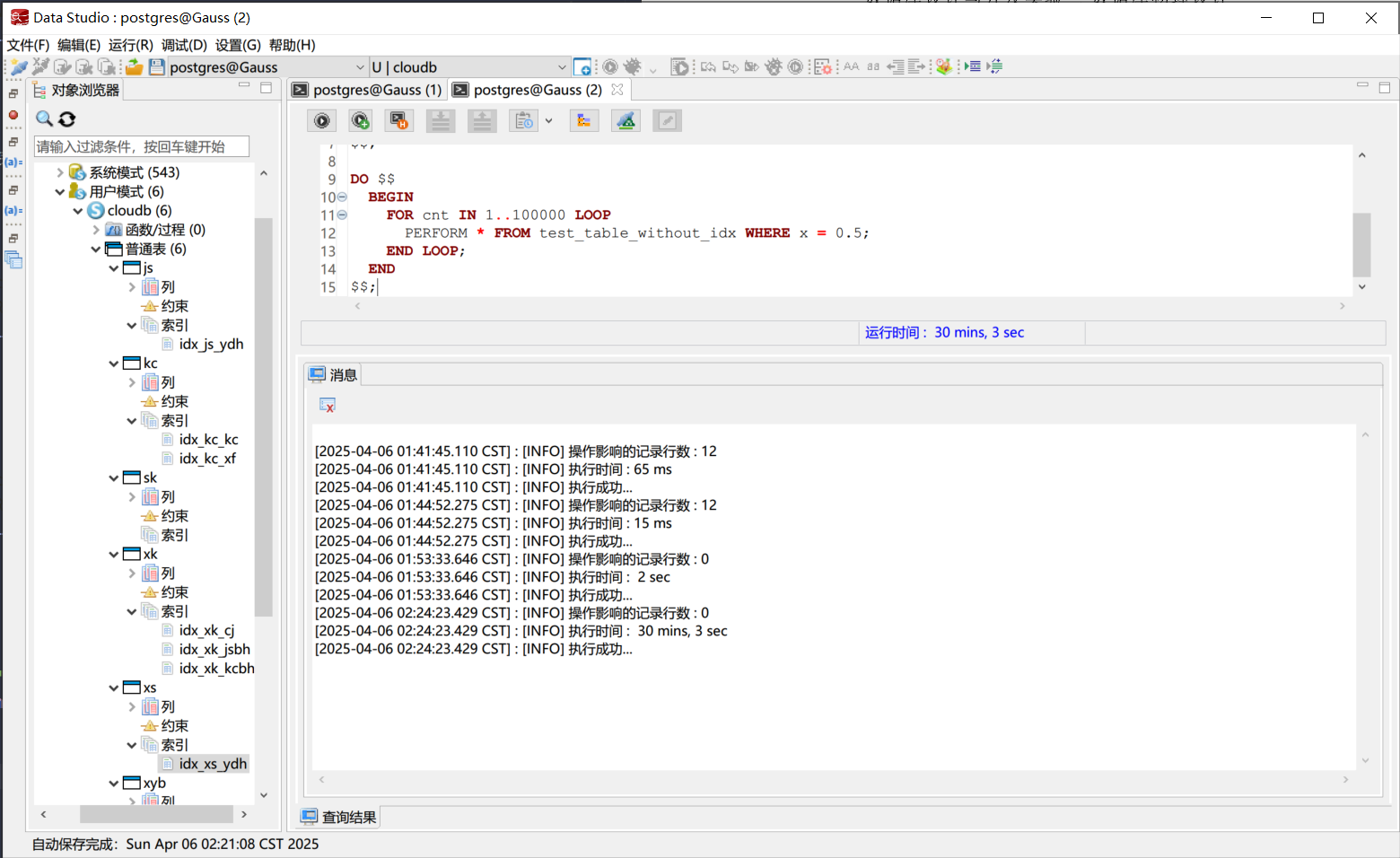 没有索引的查询
没有索引的查询使用 EXPLAIN 语句可以查看查询计划.
1
2
| EXPLAIN SELECT * FROM test_table_with_idx WHERE x = 0.5;
EXPLAIN SELECT * FROM test_table_without_idx WHERE x = 0.5;
|
#figure(
grid(columns: 2, gutter: 1em,
image(“assets/explain-with-idx.png”),
image(“assets/explain-without-idx.png”),
),
caption: “查询计划分析 (有索引, 没有索引)”,
)
可以看到, 有索引时, 查询采用 Bitmap Heap Scan, 而没有索引时, 查询采用 Seq Scan. Bitmap Heap Scan 是一种高效的查询方式, 它会先在索引中查找符合条件的记录, 然后再在数据表中查找对应的记录. 而 Seq Scan 则是顺序扫描整个数据表, 效率较低. 这也进一步证明了索引在查询中的重要性.
权限管理
以不同身份用户登录数据库建立表
使用 SSH 连接到服务器,切换到 omm 用户, 使用 gsql 命令连接到数据库。连接到数据库后,使用 CREATE USER 命令创建一个新用户。
1
| CREATE USER starlight PASSWORD 'PositionZER0@123';
|
创建成功后, 使用 \q 命令退出数据库。使用新创建的用户登录数据库。
1
| gsql -d postgres -U starlight -W PositionZER0@123
|
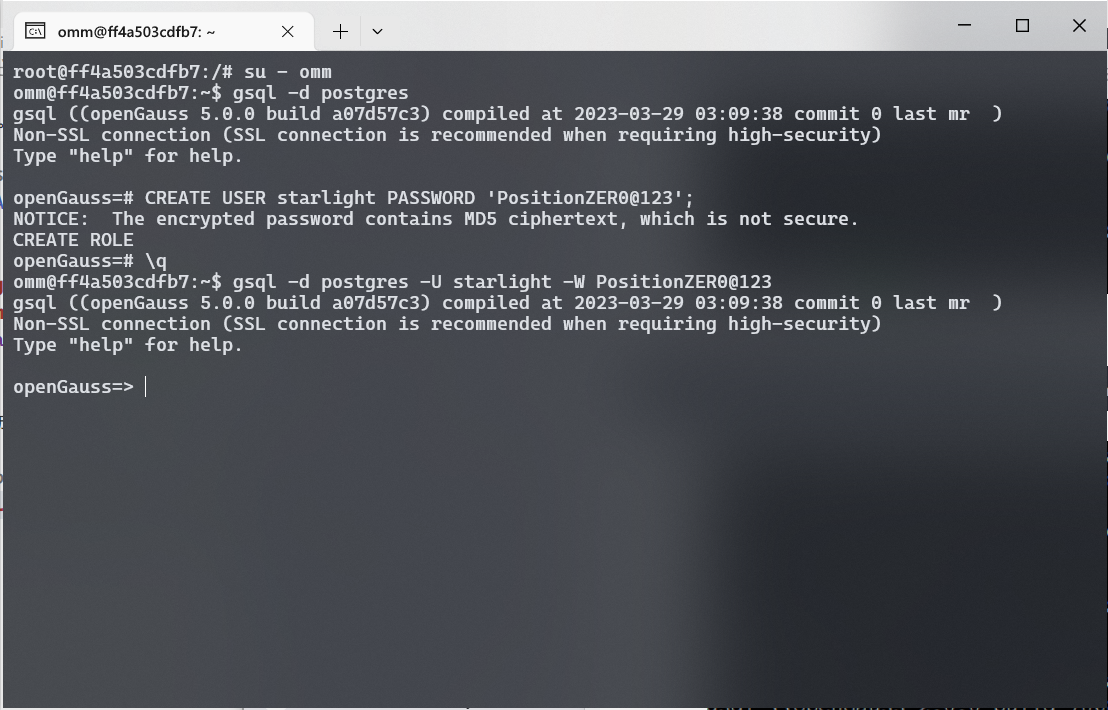 登录用户
登录用户使用与实验二中一样的语句创建学院表 xyb.
1
2
3
4
| CREATE TABLE IF NOT EXISTS xyb ( -- 创建学院表,存储学院基础信息
ydh CHAR(2) PRIMARY KEY NOT NULL, -- 学院代号,主键(不允许空,固定长度2字符)
ymc CHAR(30) NOT NULL -- 学院名称(不允许空,固定长度30字符)
);
|
执行之后, 使用 \dt 命令查看表格信息, 可以看到表格创建成功.
从 \dt 命令的结果可以发现, 尽管表名相同, 但是表格的 Schema 不同. 用户 starlight 建立的 xyb 表格在 starlight 这一 Schema 下. 这说明了不同用户创建的表格是相互独立的, 互不影响.
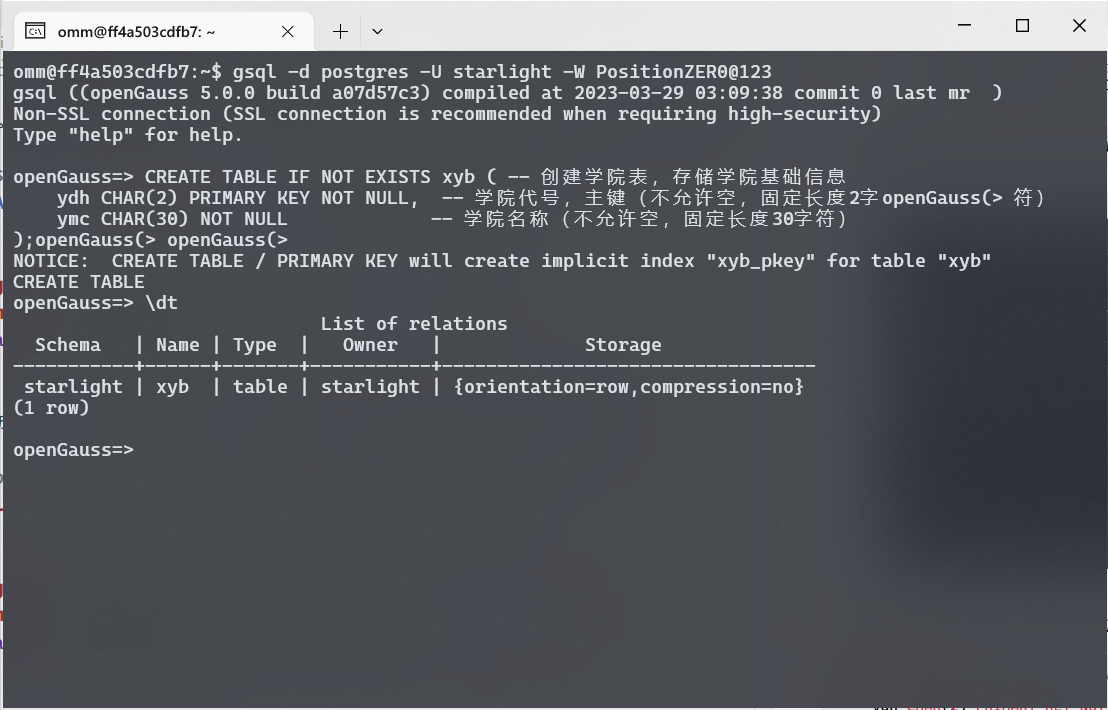 创建学院表
创建学院表向 xyb 表格中插入不同数据, 便于后续实验中进行区分.
以不同身份用户查询自己与其他用户建立的表
以用户 starlight 登录数据库, 使用 \dt 命令查看表格信息. 可以看到, 该用户只能看到自己创建的表格, 不能看到其他用户创建的表格.
使用 SELECT 语句查询用户 starlight 创建的 xyb 表格.
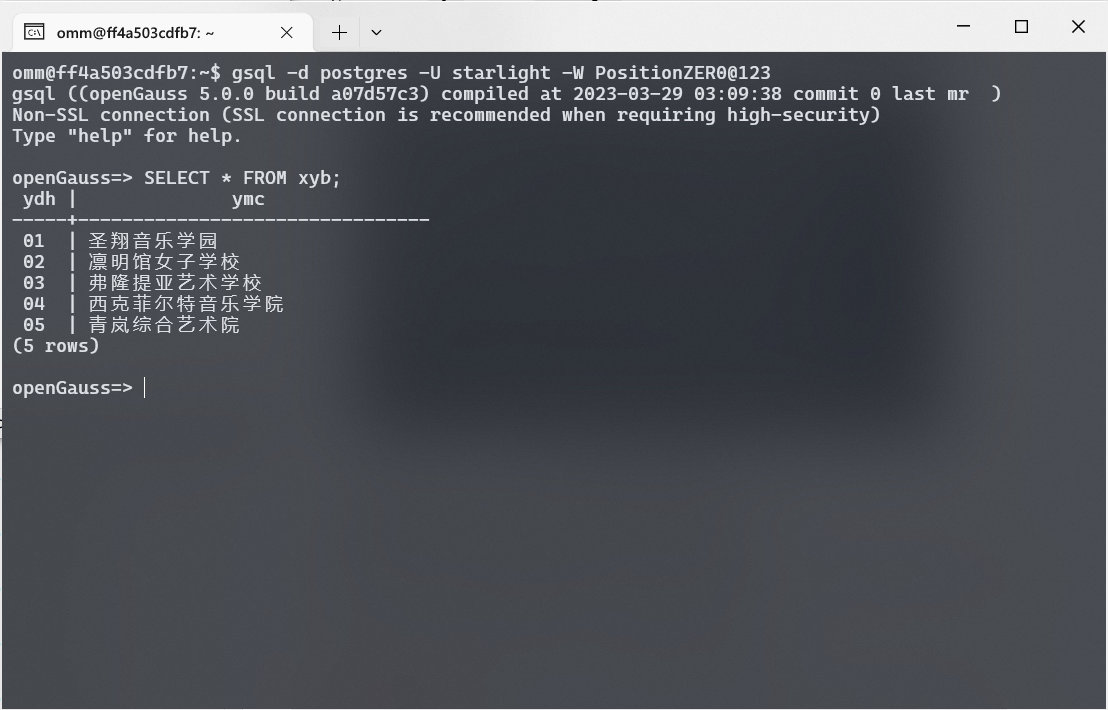 查询自己创建的表格
查询自己创建的表格若需要查询用户 cloudb 创建的 xyb 表格, 如果直接使用 SELECT 语句, 会提示权限拒绝. 这是因为用户 starlight 没有权限访问其他用户创建的表格.
1
| SELECT * FROM cloudb.xyb;
|
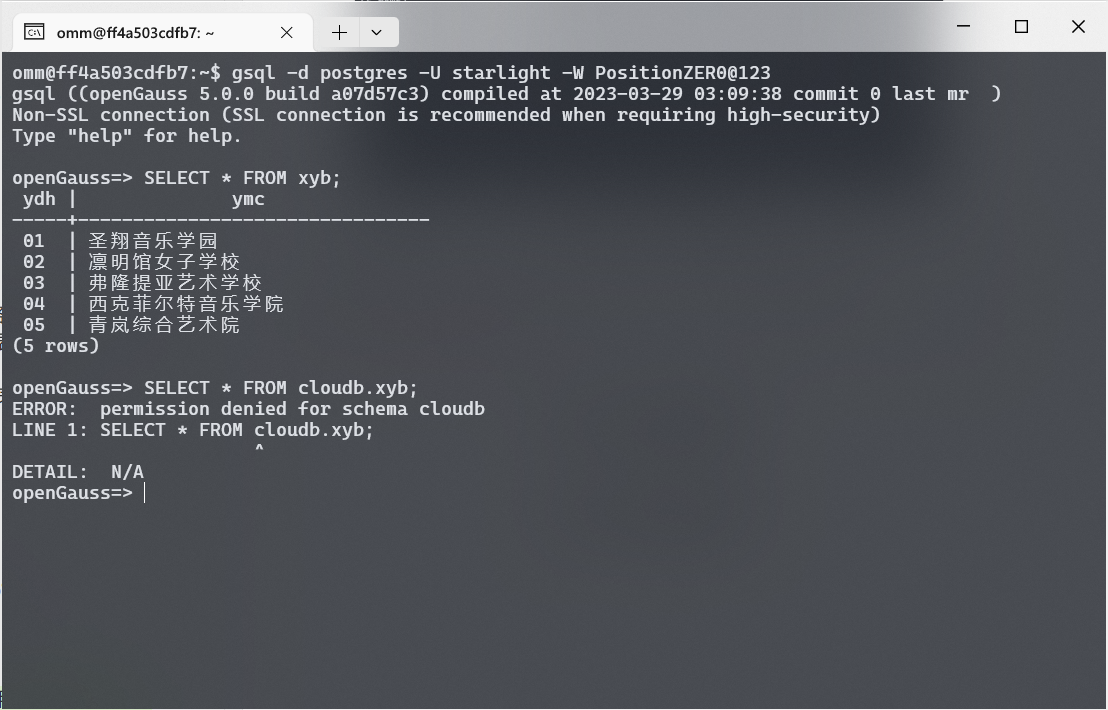 查询其他用户创建的表格提示权限拒绝
查询其他用户创建的表格提示权限拒绝若要给予用户 starlight 访问用户 cloudb 创建的 xyb 表格的权限, 需要使用 GRANT 命令. 以用户 omm 登录数据库, 使用 GRANT 命令给予用户 starlight Schema和对应表格的访问权限.
1
2
| GRANT USAGE ON SCHEMA cloudb TO starlight;
GRANT SELECT ON TABLE cloudb.xyb TO starlight;
|
执行成功后, 以用户 starlight 登录数据库, 使用 SELECT 语句查询用户 cloudb 创建的 xyb 表格.
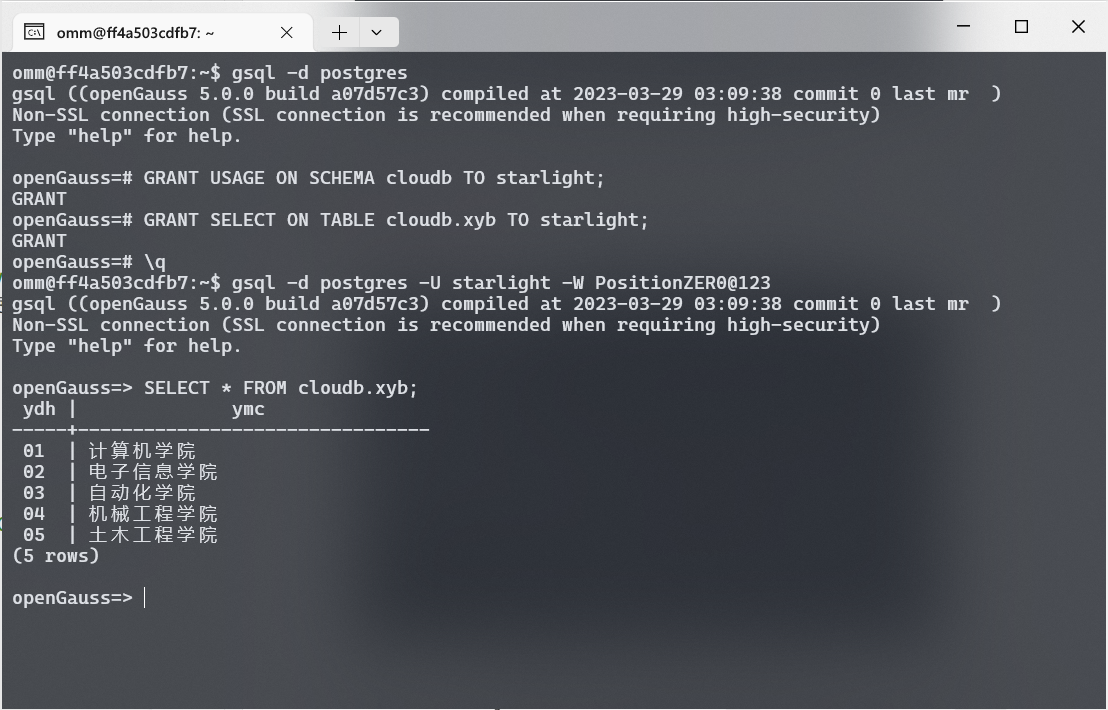 授权后成功查询其他用户创建的表格
授权后成功查询其他用户创建的表格定义授权方案并进行验证
例如需要给予用户 starlight 对用户 cloudb 创建的 xyb 表格的访问权限, 对 xs 表格的访问与修改权限, 对 xk 表无访问权限. 这时可以使用 GRANT 命令给予用户 starlight 对应的权限.
1
2
3
| GRANT USAGE ON SCHEMA cloudb TO starlight;
GRANT SELECT ON TABLE cloudb.xyb TO starlight;
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLE cloudb.xs TO starlight;
|
执行成功后, 以用户 starlight 登录数据库, 使用 SELECT 语句可顺利查询用户 cloudb 创建的 xyb 表格;
使用 INSERT, UPDATE, DELETE 语句可顺利修改到用户 cloudb 创建的 xs 表格;
使用 SELECT 语句查询用户 cloudb 创建的 xk 表格时, 提示权限拒绝.
1
2
3
| SELECT * FROM cloudb.xyb;
INSERT INTO cloudb.xs (xm, xh, ydh, bj, chrq, xb) VALUES ('巴珠绪', '20230111', '01', '计算机科学与技术', '2003-01-01', '女');
SELECT * FROM cloudb.xk;
|
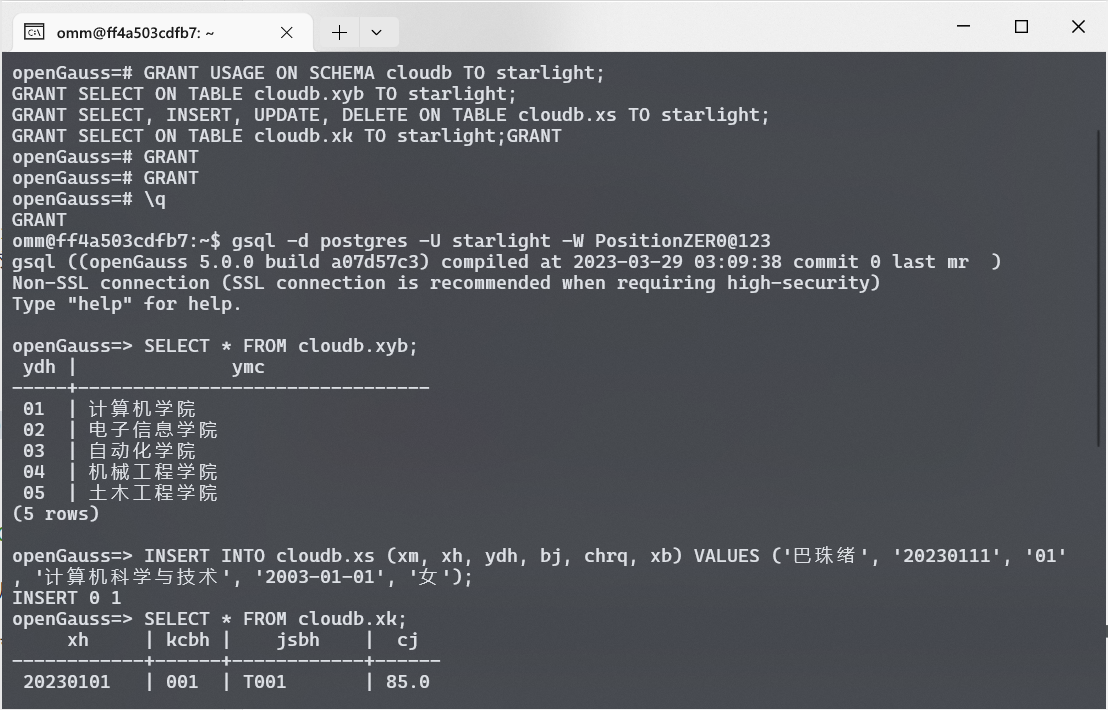 成功设置权限
成功设置权限实验结论
通过本次数据库物理设计实验,我得出了以下几点结论:
数据分区表:分区表能有效地将大量数据分散存储,提高查询和管理效率。根据实验观察,按范围分区是处理时序数据(如按年份划分的学生信息)的有效策略。
主键与外键约束:
- 修改或删除被外键引用的主键数据需要特别小心。如果没有设置合适的级联操作,数据库会拒绝执行违反引用完整性的操作。
- 使用
ON UPDATE CASCADE 和 ON DELETE CASCADE 选项可以自动维护引用完整性,避免手动处理依赖关系的繁琐步骤。 - 当涉及复杂的关系结构时,必须按照依赖关系的逆序进行删除操作。
索引的重要性:
- 实验证明索引对查询性能的影响是巨大的。在含有10万条记录的表上,有索引的查询比无索引查询快约900倍。
- 通过
EXPLAIN 命令分析,可以看到有索引时数据库使用 Bitmap Heap Scan 等高效的查询方式,而无索引时只能使用 Sequential Scan。 - 索引的效果随数据量增加而更加显著,对大规模数据库系统尤为重要。
子查询在数据操作中的应用:使用子查询可以实现复杂的数据筛选和操作,提高SQL语句的表达能力和灵活性。
实验体会
本次实验让我深入理解了数据库物理设计的重要性和复杂性。以下是我的主要体会:
数据库性能优化的关键:物理设计直接影响数据库的性能。合理的索引设计、表分区策略和约束定义能显著提升查询效率,尤其在大规模数据环境下。
权衡与取舍:数据库设计涉及多方面的权衡。例如,添加索引提高查询性能,但会占用存储空间并可能降低写入性能;CASCADE操作简化了数据管理,但可能导致意外的大规模数据删除。
实验与验证的重要性:理论知识需要通过实验验证和巩固。例如,索引对性能的影响虽然在理论上清晰,但通过实际测量两种情况下的查询时间,我对索引的重要性有了更直观的认识。
数据完整性与业务逻辑:数据库约束(如外键)不仅是技术实现,也反映了业务规则和数据完整性要求。合理设计约束可以防止错误数据的产生。